131.分割回文串
力扣题目链接
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例:
输入: “aab”
输出:
[
[“aa”,“b”],
[“a”,“a”,“b”]
]
思路
本题这涉及到两个关键问题:
- 切割问题,有不同的切割方式
- 判断回文
这种题目,想用for循环暴力解法,可能都不那么容易写出来,所以要换一种暴力的方式,就是回溯。
切割,其实切割问题类似组合问题。
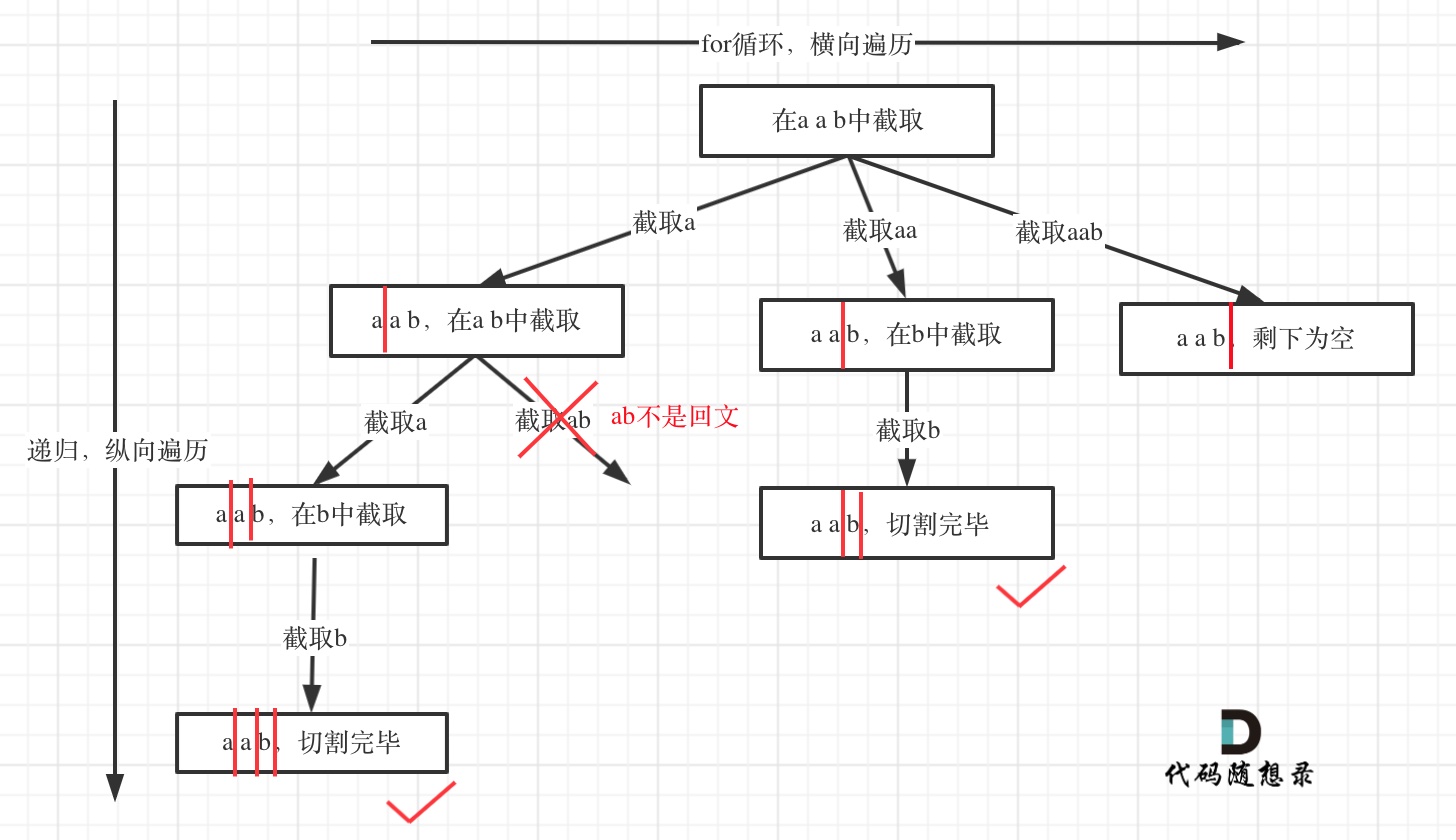
例如对于字符串abcdef:
- 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个…。
- 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段…。
所以切割问题,也可以抽象为一棵树形结构,如图:

递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
此时可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。
回溯三部曲
全局变量数组path存放切割后回文的子串,二维数组result存放结果集。 (这两个参数可以放到函数参数里)
本题递归函数参数还需要startIndex,因为切割过的地方,不能重复切割,和组合问题也是保持一致的。
在回溯算法:求组合总和(二)中深入探讨了组合问题什么时候需要startIndex,什么时候不需要startIndex。
代码如下:
1
2
3
| vector<vector<string>> result;
vector<string> path;
void backtracking (const string& s, int startIndex) {
|
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止条件。
那么在代码里什么是切割线呢?
在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
所以终止条件代码如下:
1
2
3
4
5
6
7
| void backtracking (const string& s, int startIndex) {
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
}
|
来看看在递归循环中如何截取子串呢?
在for (int i = startIndex; i < s.size(); i++)循环中, 定义了起始位置startIndex,那么 [startIndex, i] 就是要截取的子串。
首先判断这个子串是不是回文,如果是回文,就加入在vector<string> path中,path用来记录切割过的回文子串。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
| for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome(s, startIndex, i)) {
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else {
continue;
}
backtracking(s, i + 1);
path.pop_back();
}
|
注意切割过的位置,不能重复切割,所以,backtracking(s, i + 1); 传入下一层的起始位置为i + 1。
判断回文子串
最后看一下回文子串要如何判断了,判断一个字符串是否是回文。
可以使用双指针法,一个指针从前向后,一个指针从后向前,如果前后指针所指向的元素是相等的,就是回文字符串了。
那么判断回文的C++代码如下:
1
2
3
4
5
6
7
8
| bool isPalindrome(const string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
if (s[i] != s[j]) {
return false;
}
}
return true;
}
|
此时关键代码已经讲解完毕,整体代码如下:
根据回溯算法模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
| void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表);
回溯,撤销处理结果
}
}
|
不难写出如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| class Solution {
private:
vector<vector<string>> result;
vector<string> path;
void backtracking (const string& s, int startIndex) {
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome(s, startIndex, i)) {
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else {
continue;
}
backtracking(s, i + 1);
path.pop_back();
}
}
bool isPalindrome(const string& s, int start, int end) {
for (int i = start, j = end; i < j; i++, j--) {
if (s[i] != s[j]) {
return false;
}
}
return true;
}
public:
vector<vector<string>> partition(string s) {
result.clear();
path.clear();
backtracking(s, 0);
return result;
}
};
|
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n^2)
优化
上面的代码还存在一定的优化空间, 在于如何更高效的计算一个子字符串是否是回文字串。上述代码isPalindrome函数运用双指针的方法来判定对于一个字符串s, 给定起始下标和终止下标, 截取出的子字符串是否是回文字串。但是其中有一定的重复计算存在:
例如给定字符串"abcde", 在已知"bcd"不是回文字串时, 不再需要去双指针操作"abcde"而可以直接判定它一定不是回文字串。
具体来说, 给定一个字符串s, 长度为n, 它成为回文字串的充分必要条件是s[0] == s[n-1]且s[1:n-1]是回文字串。
大家如果熟悉动态规划这种算法的话, 可以高效地事先一次性计算出, 针对一个字符串s, 它的任何子串是否是回文字串, 然后在的回溯函数中直接查询即可, 省去了双指针移动判定这一步骤.
具体参考代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| class Solution {
private:
vector<vector<string>> result;
vector<string> path;
vector<vector<bool>> isPalindrome;
void backtracking (const string& s, int startIndex) {
if (startIndex >= s.size()) {
result.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isPalindrome[startIndex][i]) {
string str = s.substr(startIndex, i - startIndex + 1);
path.push_back(str);
} else {
continue;
}
backtracking(s, i + 1);
path.pop_back();
}
}
void computePalindrome(const string& s) {
isPalindrome.resize(s.size(), vector<bool>(s.size(), false));
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i; j < s.size(); j++) {
if (j == i) {isPalindrome[i][j] = true;}
else if (j - i == 1) {isPalindrome[i][j] = (s[i] == s[j]);}
else {isPalindrome[i][j] = (s[i] == s[j] && isPalindrome[i+1][j-1]);}
}
}
}
public:
vector<vector<string>> partition(string s) {
result.clear();
path.clear();
computePalindrome(s);
backtracking(s, 0);
return result;
}
};
|
总结
这道题目在leetcode上是中等,但可以说是hard的题目了,但是代码其实就是按照模板的样子来的。
那么难究竟难在什么地方呢?
我列出如下几个难点:
- 切割问题可以抽象为组合问题
- 如何模拟那些切割线
- 切割问题中递归如何终止
- 在递归循环中如何截取子串
- 如何判断回文
平时在做难题的时候,总结出来难究竟难在哪里也是一种需要锻炼的能力。
一些同学可能遇到题目比较难,但是不知道题目难在哪里,反正就是很难。其实这样还是思维不够清晰,这种总结的能力需要多接触多锻炼。
本题我相信很多同学主要卡在了第一个难点上:就是不知道如何切割,甚至知道要用回溯法,也不知道如何用。也就是没有体会到按照求组合问题的套路就可以解决切割。
如果意识到这一点,算是重大突破了。接下来就可以对着模板照葫芦画瓢。
但接下来如何模拟切割线,如何终止,如何截取子串,其实都不好想,最后判断回文算是最简单的了。
关于模拟切割线,其实就是index是上一层已经确定了的分割线,i是这一层试图寻找的新分割线
除了这些难点,本题还有细节,例如:切割过的地方不能重复切割所以递归函数需要传入i + 1。
所以本题应该是一道hard题目了。
可能刷过这道题目的录友都没感受到自己原来克服了这么多难点,就把这道题目AC了,这应该叫做无招胜有招,人码合一。
93.复原IP地址
力扣题目链接
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:“0.1.2.201” 和 “192.168.1.1” 是 有效的 IP 地址,但是 “0.011.255.245”、“192.168.1.312” 和 “192.168@1.1” 是 无效的 IP 地址。
示例 1:
- 输入:s = “25525511135”
- 输出:[“255.255.11.135”,“255.255.111.35”]
示例 2:
- 输入:s = “0000”
- 输出:[“0.0.0.0”]
示例 3:
- 输入:s = “1111”
- 输出:[“1.1.1.1”]
示例 4:
- 输入:s = “010010”
- 输出:[“0.10.0.10”,“0.100.1.0”]
示例 5:
- 输入:s = “101023”
- 输出:[“1.0.10.23”,“1.0.102.3”,“10.1.0.23”,“10.10.2.3”,“101.0.2.3”]
提示:
- 0 <= s.length <= 3000
- s 仅由数字组成
思路
切割问题可以使用回溯搜索法把所有可能性搜出来,和刚做过的131.分割回文串就十分类似。
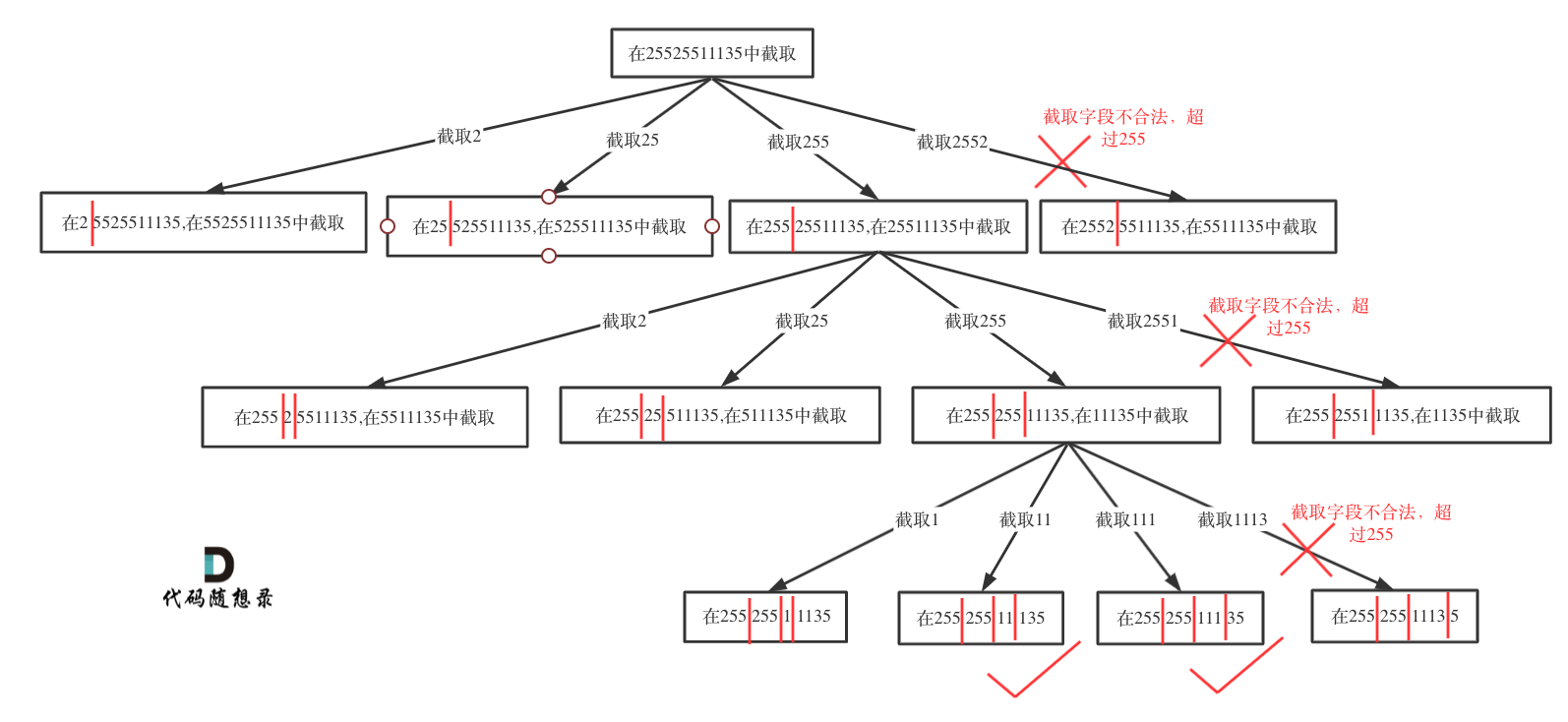
切割问题可以抽象为树型结构,如图:
回溯三部曲
在131.分割回文串中就提到切割问题类似组合问题。
startIndex一定是需要的,因为不能重复分割,记录下一层递归分割的起始位置。
本题还需要一个变量pointNum,记录添加逗点的数量。
所以代码如下:
1
2
3
| vector<string> result;
void backtracking(string& s, int startIndex, int pointNum) {
|
终止条件和131.分割回文串情况就不同了,本题明确要求只会分成4段,所以不能用切割线切到最后作为终止条件,而是分割的段数作为终止条件。
pointNum表示逗点数量,pointNum为3说明字符串分成了4段了。
然后验证一下第四段是否合法,如果合法就加入到结果集里
代码如下:
1
2
3
4
5
6
7
| if (pointNum == 3) {
if (isValid(s, startIndex, s.size() - 1)) {
result.push_back(s);
}
return;
}
|
在131.分割回文串中已经讲过在循环遍历中如何截取子串。
在for (int i = startIndex; i < s.size(); i++)循环中 [startIndex, i] 这个区间就是截取的子串,需要判断这个子串是否合法。
如果合法就在字符串后面加上符号.表示已经分割。
如果不合法就结束本层循环,如图中剪掉的分支:
然后就是递归和回溯的过程:
递归调用时,下一层递归的startIndex要从i+2开始(因为需要在字符串中加入了分隔符.),同时记录分割符的数量pointNum 要 +1。
回溯的时候,就将刚刚加入的分隔符. 删掉就可以了,pointNum也要-1。
代码如下:
1
2
3
4
5
6
7
8
9
| for (int i = startIndex; i < s.size(); i++) {
if (isValid(s, startIndex, i)) {
s.insert(s.begin() + i + 1 , '.');
pointNum++;
backtracking(s, i + 2, pointNum);
pointNum--;
s.erase(s.begin() + i + 1);
} else break;
}
|
判断子串是否合法
最后就是在写一个判断段位是否是有效段位了。
主要考虑到如下三点:
- 段位以0为开头的数字不合法
- 段位里有非正整数字符不合法
- 段位如果大于255了不合法
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) {
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') {
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) {
return false;
}
}
return true;
}
|
根据关于回溯算法,你该了解这些!给出的回溯算法模板:
1
2
3
4
5
6
7
8
9
10
11
12
| void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
|
可以写出如下回溯算法C++代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| class Solution {
private:
vector<string> result;
void backtracking(string& s, int startIndex, int pointNum) {
if (pointNum == 3) {
if (isValid(s, startIndex, s.size() - 1)) {
result.push_back(s);
}
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (isValid(s, startIndex, i)) {
s.insert(s.begin() + i + 1 , '.');
pointNum++;
backtracking(s, i + 2, pointNum);
pointNum--;
s.erase(s.begin() + i + 1);
} else break;
}
}
bool isValid(const string& s, int start, int end) {
if (start > end) {
return false;
}
if (s[start] == '0' && start != end) {
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s[i] > '9' || s[i] < '0') {
return false;
}
num = num * 10 + (s[i] - '0');
if (num > 255) {
return false;
}
}
return true;
}
public:
vector<string> restoreIpAddresses(string s) {
result.clear();
if (s.size() < 4 || s.size() > 12) return result;
backtracking(s, 0, 0);
return result;
}
};
|
- 时间复杂度: O(3^4),IP地址最多包含4个数字,每个数字最多有3种可能的分割方式,则搜索树的最大深度为4,每个节点最多有3个子节点。
- 空间复杂度: O(n)
总结
在131.分割回文串中我列举的分割字符串的难点,本题都覆盖了。
而且本题还需要操作字符串添加逗号作为分隔符,并验证区间的合法性。
可以说是131.分割回文串的加强版。
在本文的树形结构图中,我已经把详细的分析思路都画了出来,相信大家看了之后一定会思路清晰不少!
78.子集
力扣题目链接
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: nums = [1,2,3]
输出:
[
[3],
[1],
[2],
[1,2,3],
[1,3],
[2,3],
[1,2],
[]
]
思路
求子集问题和77.组合和131.分割回文串又不一样了。
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
有同学问了,什么时候for可以从0开始呢?
求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合,排列问题后续的文章就会讲到的。
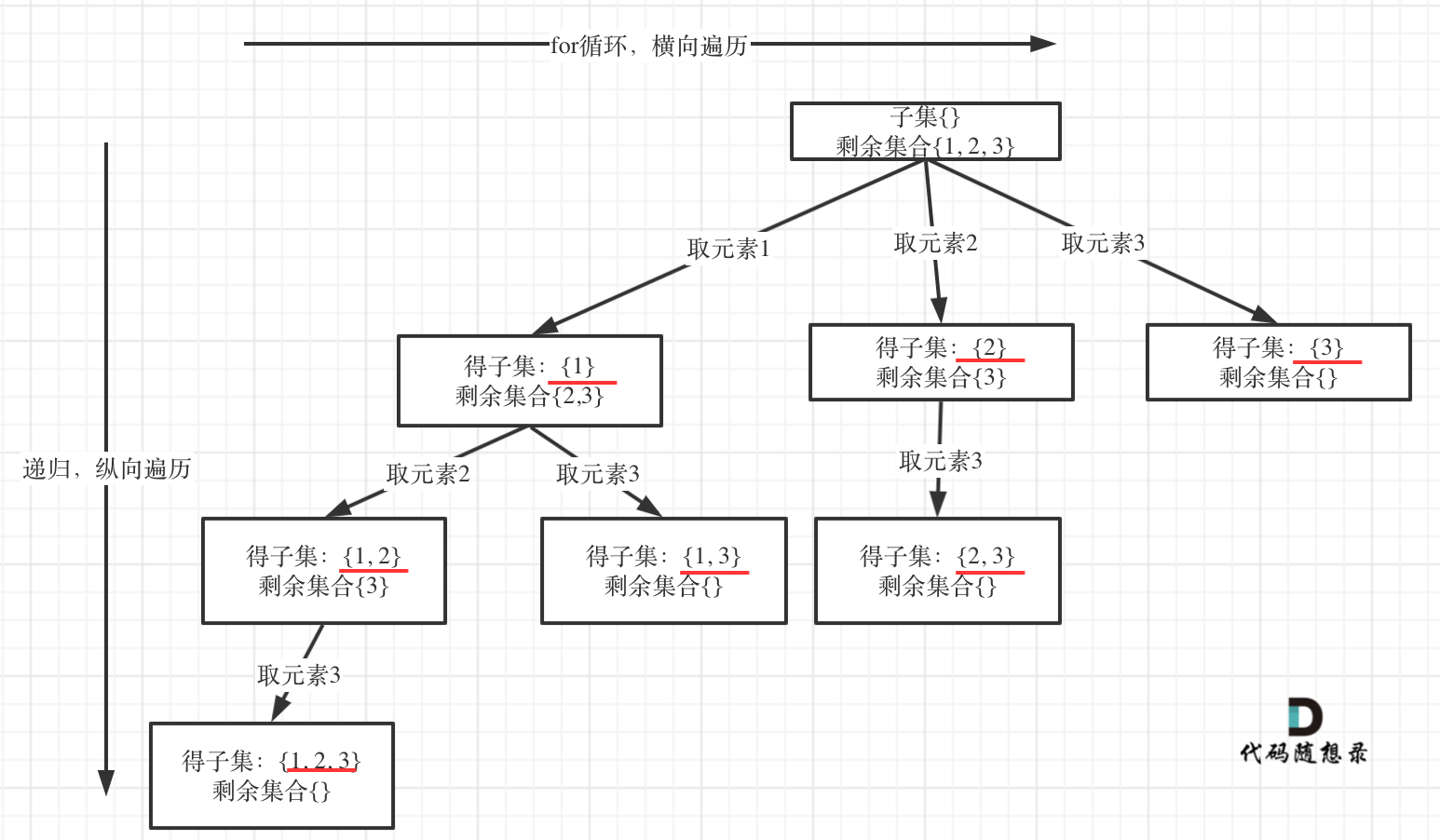
以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下:
从图中红线部分,可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合。
回溯三部曲
全局变量数组path为子集收集元素,二维数组result存放子集组合。(也可以放到递归函数参数里)
递归函数参数在上面讲到了,需要startIndex。
代码如下:
1
2
3
| vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
|
递归终止条件
从图中可以看出:
剩余集合为空的时候,就是叶子节点。
那么什么时候剩余集合为空呢?
就是startIndex已经大于数组的长度了,就终止了,因为没有元素可取了,代码如下:
1
2
3
| if (startIndex >= nums.size()) {
return;
}
|
其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了。
求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树。
那么单层递归逻辑代码如下:
1
2
3
4
5
| for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]); // 子集收集元素
backtracking(nums, i + 1); // 注意从i+1开始,元素不重复取
path.pop_back(); // 回溯
}
|
根据关于回溯算法,你该了解这些!给出的回溯算法模板:
1
2
3
4
5
6
7
8
9
10
11
12
| void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
|
可以写出如下回溯算法C++代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path);
if (startIndex >= nums.size()) {
return;
}
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsets(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
|
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
在注释中,可以发现可以不写终止条件,因为本来就要遍历整棵树。
有的同学可能担心不写终止条件会不会无限递归?
并不会,因为每次递归的下一层就是从i+1开始的。
总结
相信大家经过了
洗礼之后,发现子集问题还真的有点简单了,其实这就是一道标准的模板题。
但是要清楚子集问题和组合问题、分割问题的的区别,子集是收集树形结构中树的所有节点的结果。
而组合问题、分割问题是收集树形结构中叶子节点的结果。
90.子集II
力扣题目链接
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
- 输入: [1,2,2]
- 输出:
[
[2],
[1],
[1,2,2],
[2,2],
[1,2],
[]
]
思路
做本题之前一定要先做78.子集。
这道题目和78.子集区别就是集合里有重复元素了,而且求取的子集要去重。
那么关于回溯算法中的去重问题,在40.组合总和II中已经详细讲解过了,和本题是一个套路。
剧透一下,后期要讲解的排列问题里去重也是这个套路,所以理解“树层去重”和“树枝去重”非常重要。
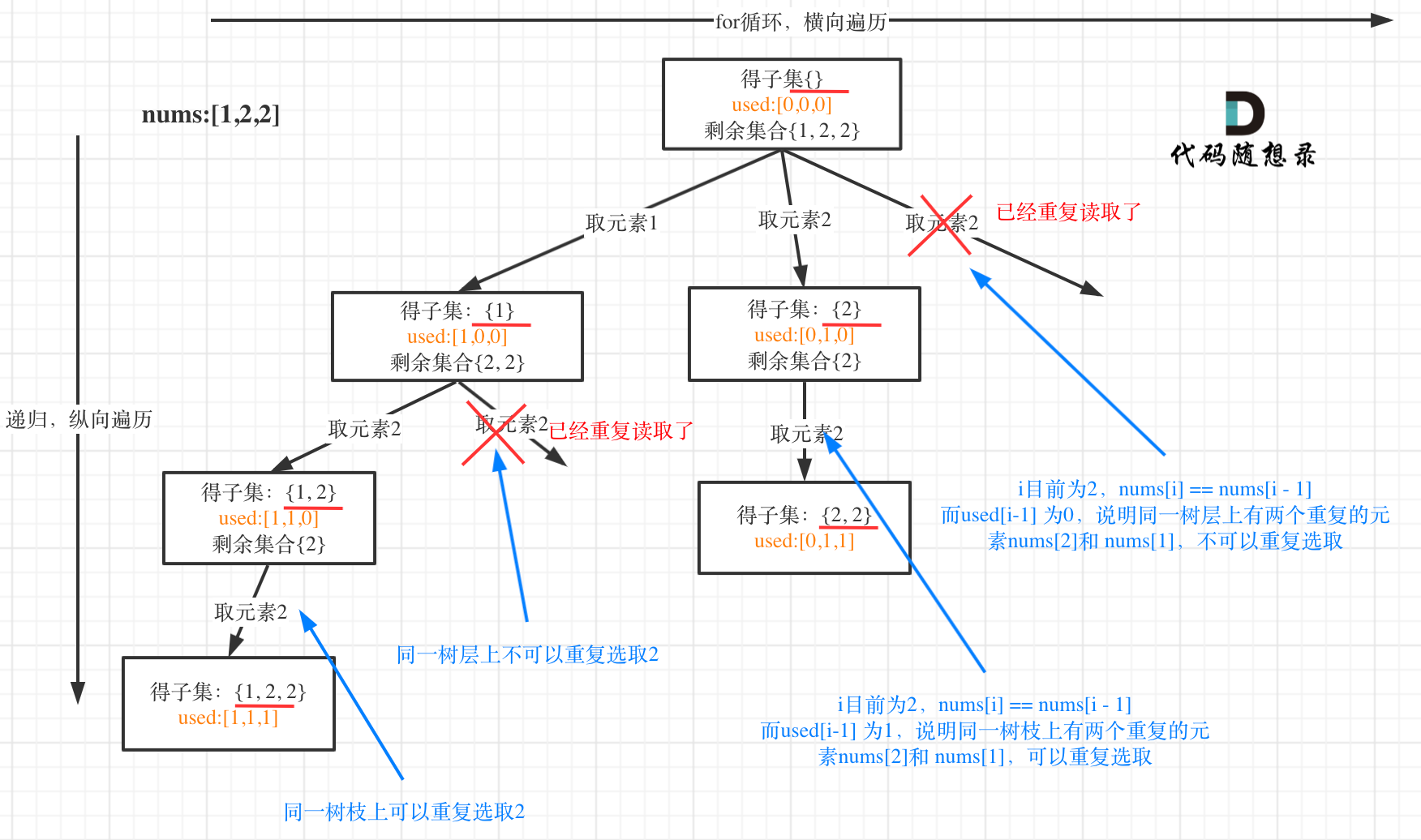
用示例中的[1, 2, 2] 来举例,如图所示: (注意去重需要先对集合排序)
从图中可以看出,同一树层上重复取2 就要过滤掉,同一树枝上就可以重复取2,因为同一树枝上元素的集合才是唯一子集!
本题就是其实就是回溯算法:求子集问题!的基础上加上了去重,去重在回溯算法:求组合总和(三)也讲过了,所以我就直接给出代码了:
C++代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex, vector<bool>& used) {
result.push_back(path);
for (int i = startIndex; i < nums.size(); i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, i + 1, used);
used[i] = false;
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
sort(nums.begin(), nums.end());
backtracking(nums, 0, used);
return result;
}
};
|
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
使用set去重的版本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path);
unordered_set<int> uset;
for (int i = startIndex; i < nums.size(); i++) {
if (uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end());
backtracking(nums, 0);
return result;
}
};
|
补充
本题也可以不使用used数组来去重,因为递归的时候下一个startIndex是i+1而不是0。
如果要是全排列的话,每次要从0开始遍历,为了跳过已入栈的元素,需要使用used。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
result.push_back(path);
for (int i = startIndex; i < nums.size(); i++) {
if (i > startIndex && nums[i] == nums[i - 1] ) {
continue;
}
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
result.clear();
path.clear();
sort(nums.begin(), nums.end());
backtracking(nums, 0);
return result;
}
};
|
总结
其实这道题目的知识点,之前都讲过了,如果之前讲过的子集问题和去重问题都掌握的好,这道题目应该分分钟AC。
当然本题去重的逻辑,也可以这么写
1
2
3
| if (i > startIndex && nums[i] == nums[i - 1] ) {
continue;
}
|
491.递增子序列
力扣题目链接
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例:
- 输入: [4, 6, 7, 7]
- 输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
说明:
- 给定数组的长度不会超过15。
- 数组中的整数范围是 [-100,100]。
- 给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。
思路
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的90.子集II。
就是因为太像了,更要注意差别所在,要不就掉坑里了!
在90.子集II中是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
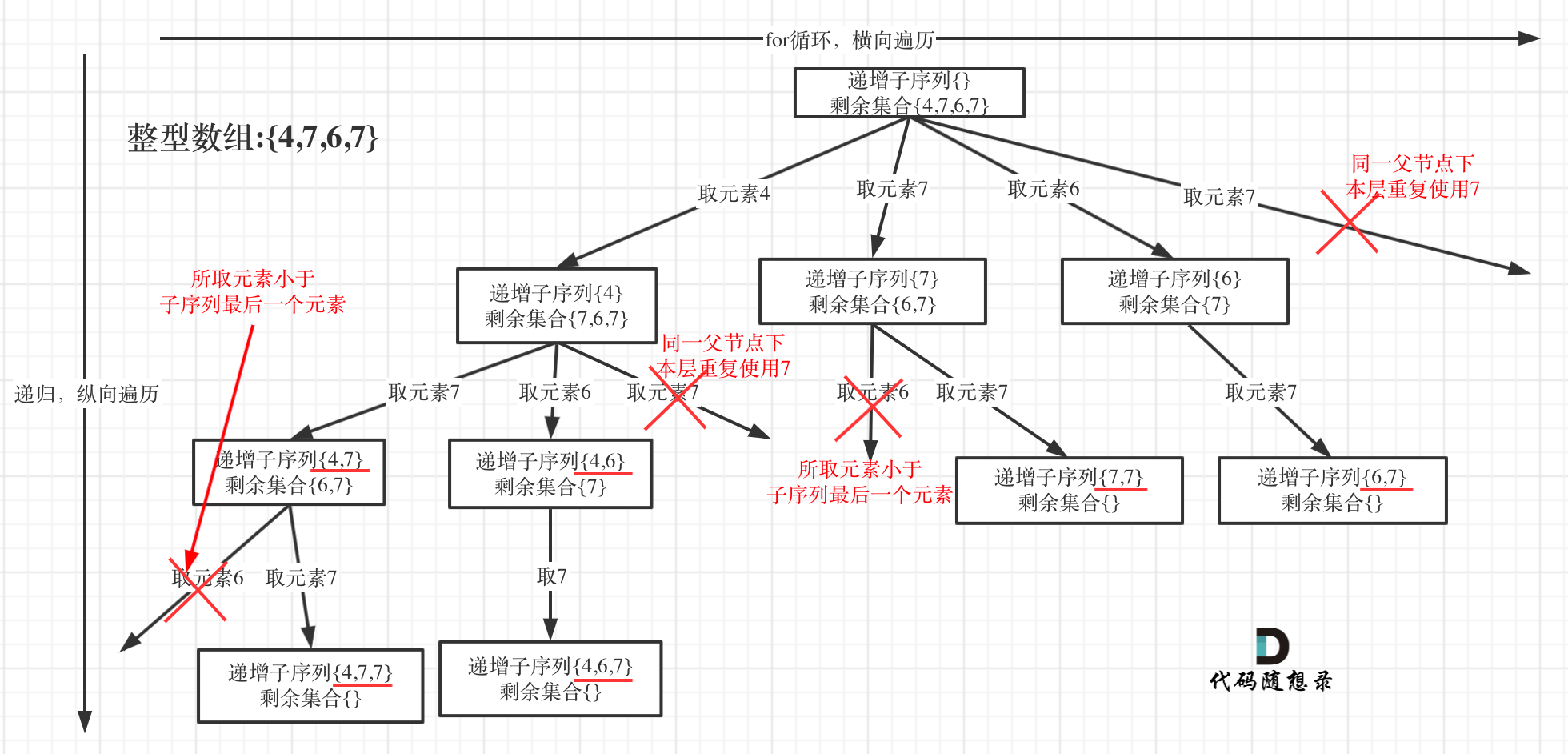
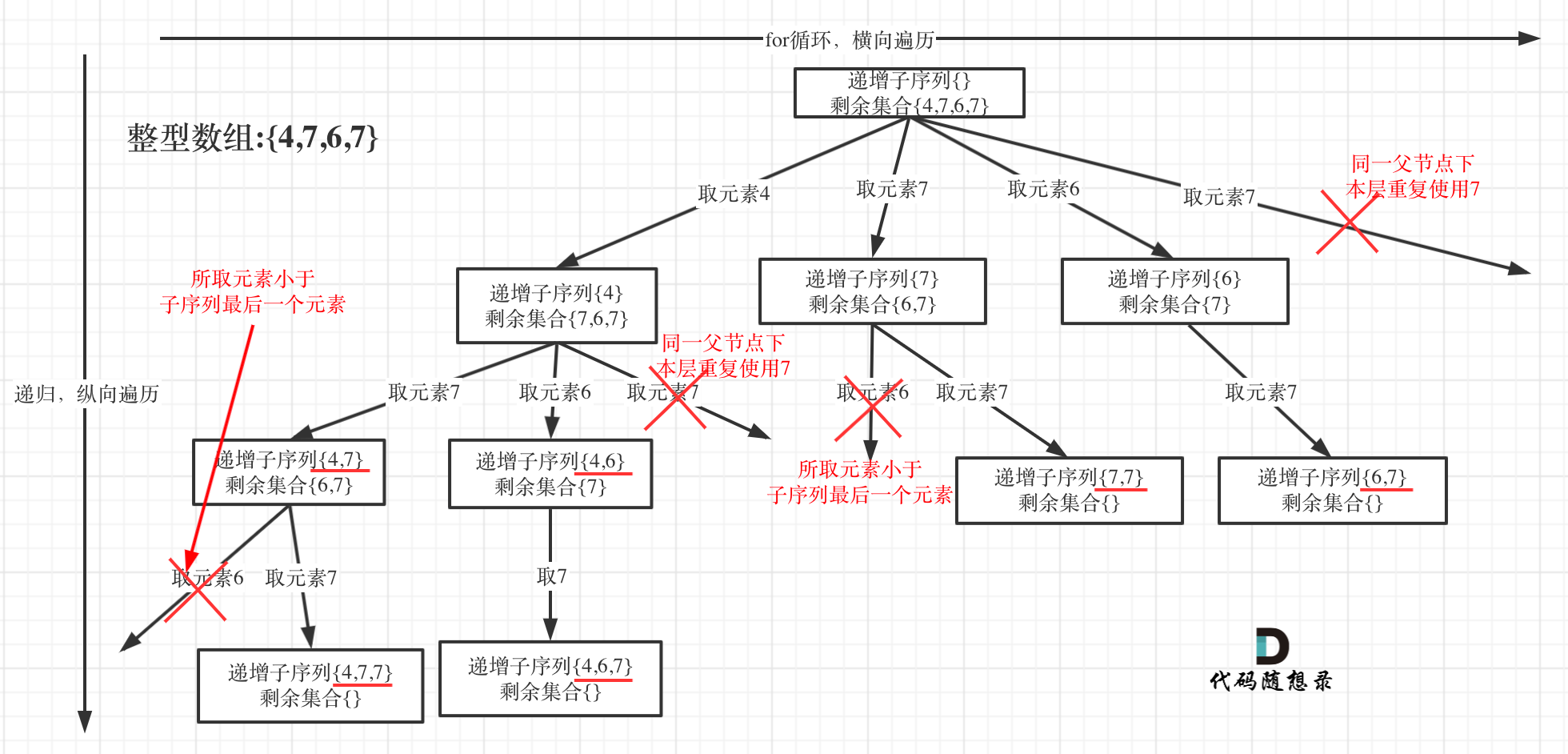
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。
为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:
回溯三部曲
本题求子序列,很明显一个元素不能重复使用,所以需要startIndex,调整下一层递归的起始位置。
代码如下:
1
2
3
| vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex)
|
本题其实类似求子集问题,也是要遍历树形结构找每一个节点,所以和回溯算法:求子集问题!一样,可以不加终止条件,startIndex每次都会加1,并不会无限递归。
但本题收集结果有所不同,题目要求递增子序列大小至少为2,所以代码如下:
1
2
3
4
| if (path.size() > 1) {
result.push_back(path);
}
|
在图中可以看出,同一父节点下的同层上使用过的元素就不能再使用了
那么单层搜索代码如下:
1
2
3
4
5
6
7
8
9
10
11
| unordered_set<int> uset;
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
|
对于已经习惯写回溯的同学,看到递归函数上面的uset.insert(nums[i]);,下面却没有对应的pop之类的操作,应该很不习惯吧
这也是需要注意的点,unordered_set<int> uset; 是记录本层元素是否重复使用,新的一层uset都会重新定义(清空),所以要知道uset只负责本层!
最后整体C++代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
if (path.size() > 1) {
result.push_back(path);
}
unordered_set<int> uset;
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end()) {
continue;
}
uset.insert(nums[i]);
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
|
- 时间复杂度: O(n * 2^n)
- 空间复杂度: O(n)
优化
以上代码用我用了unordered_set<int>来记录本层元素是否重复使用。
其实用数组来做哈希,效率就高了很多。
注意题目中说了,数值范围[-100,100],所以完全可以用数组来做哈希。
程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且每次重新定义set,insert的时候其底层的符号表也要做相应的扩充,也是费事的。
那么优化后的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
if (path.size() > 1) {
result.push_back(path);
}
int used[201] = {0};
for (int i = startIndex; i < nums.size(); i++) {
if ((!path.empty() && nums[i] < path.back())
|| used[nums[i] + 100] == 1) {
continue;
}
used[nums[i] + 100] = 1;
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
|
这份代码在leetcode上提交,要比版本一耗时要好的多。
所以正如在哈希表:总结篇!(每逢总结必经典)中说的那样,数组,set,map都可以做哈希表,而且数组干的活,map和set都能干,但如果数值范围小的话能用数组尽量用数组。
总结
本题题解清一色都说是深度优先搜索,但我更倾向于说它用回溯法,而且本题我也是完全使用回溯法的逻辑来分析的。
相信大家在本题中处处都能看到是回溯算法:求子集问题(二)的身影,但处处又都是陷阱。
对于养成思维定式或者套模板套嗨了的同学,这道题起到了很好的警醒作用。更重要的是拓展了大家的思路!