Day 5

HTTP/1.1、HTTP/2、HTTP/3 演变
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
HTTP/1.1 相比 HTTP/1.0 性能上的改进:
- 使用长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
- 支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
但 HTTP/1.1 还是有性能瓶颈:
- 请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩
Body的部分; - 发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
- 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应。
HTTP/2 做了什么优化?
HTTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。
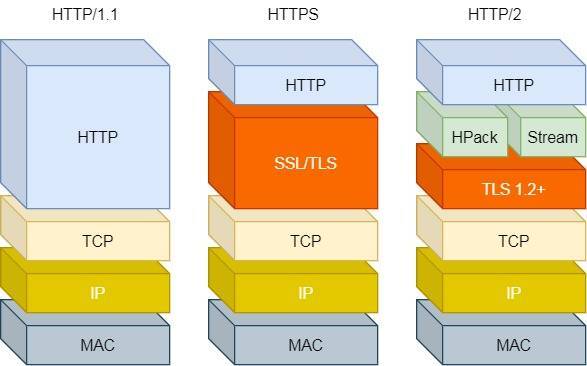
那 HTTP/2 相比 HTTP/1.1 性能上的改进:
- 头部压缩
- 二进制格式
- 并发传输
- 服务器主动推送资源
1. 头部压缩
HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。
这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
2. 二进制格式
HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧(frame):头信息帧(Headers Frame)和数据帧(Data Frame)。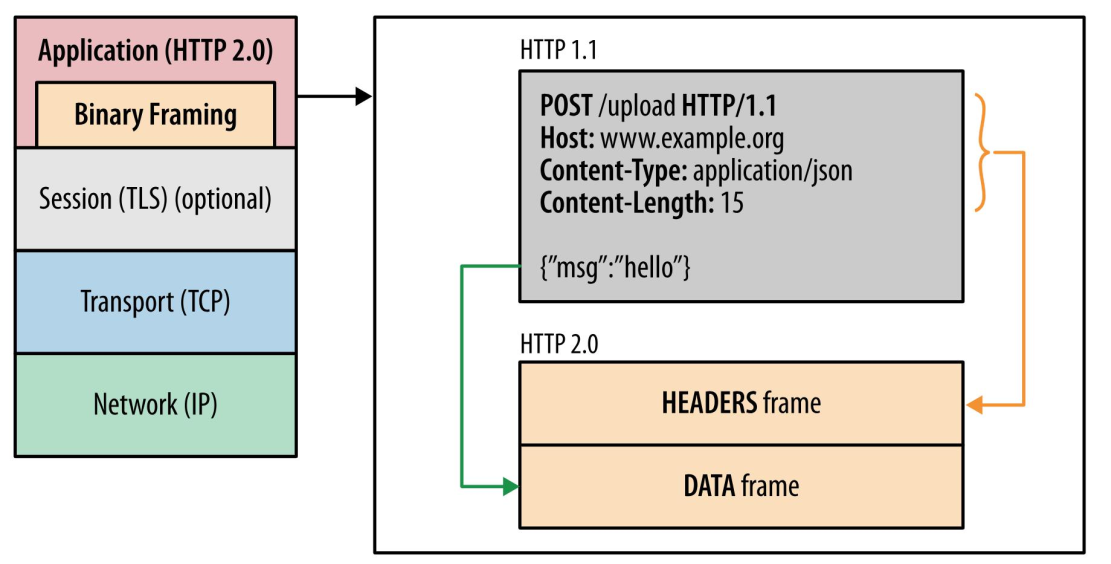
这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
比如状态码 200 ,在 HTTP/1.1 是用 ‘2’‘0’‘0’ 三个字符来表示(二进制:00110010 00110000 00110000),共用了 3 个字节,如下图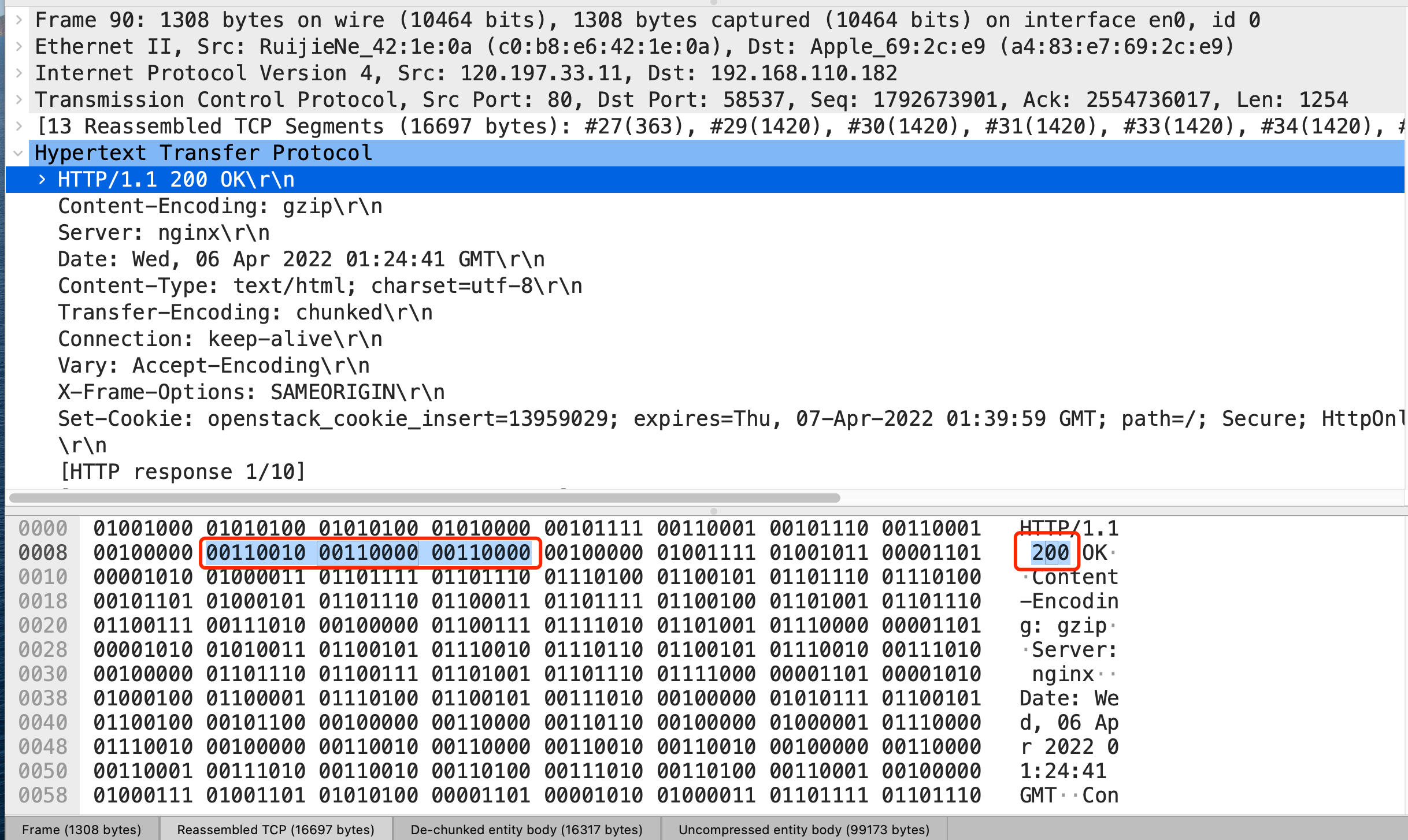
在 HTTP/2 对于状态码 200 的二进制编码是 10001000,只用了 1 字节就能表示,相比于 HTTP/1.1 节省了 2 个字节,如下图: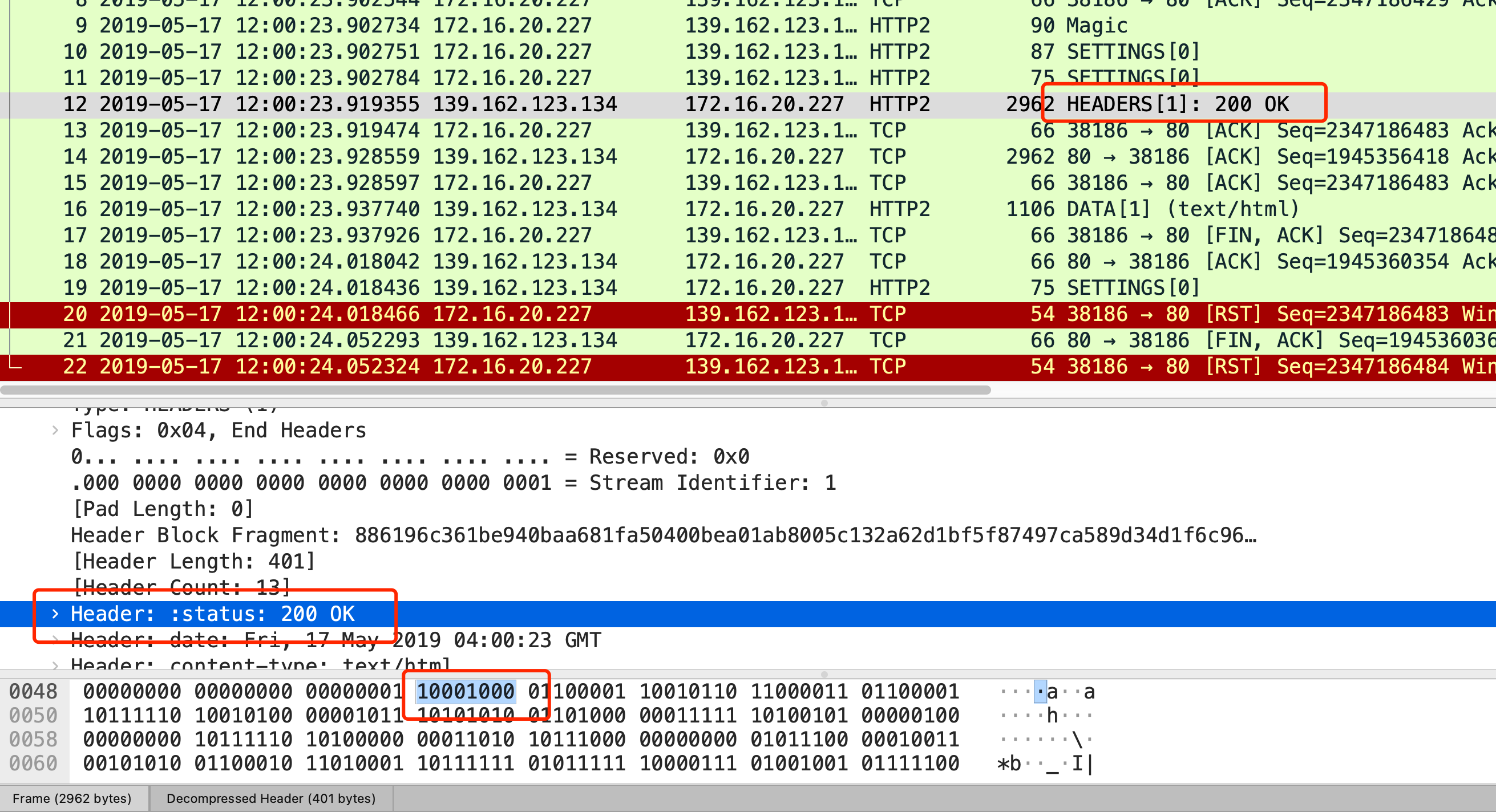
Header: :status: 200 OK 的编码内容为:1000 1000,那么表达的含义是什么呢?
- 最前面的 1 标识该 Header 是静态表中已经存在的 KV。(至于什么是静态表,可以看这篇:HTTP/2 牛逼在哪? (opens new window))
- 在静态表里,“:status: 200 ok” 静态表编码是 8,二进制即是 1000。
因此,整体加起来就是 1000 1000。
3. 并发传输
都知道 HTTP/1.1 的实现是基于请求-响应模型的。同一个连接中,HTTP 完成一个事务(请求与响应),才能处理下一个事务,也就是说在发出请求等待响应的过程中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是无法发送的,也造成了队头阻塞的问题。
而 HTTP/2 就很牛逼了,引出了 Stream 概念,多个 Stream 复用在一条 TCP 连接。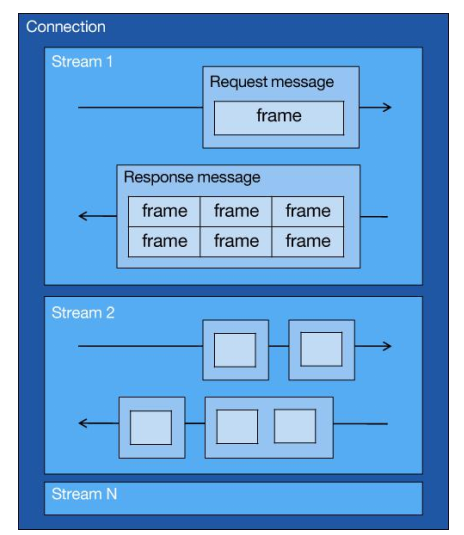
从上图可以看到,1 个 TCP 连接包含多个 Stream,Stream 里可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成。Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放 HTTP/1 中的内容(头部和包体)。
针对不同的 HTTP 请求用独一无二的 Stream ID 来区分,接收端可以通过 Stream ID 有序组装成 HTTP 消息,不同 Stream 的帧是可以乱序发送的,因此可以并发不同的 Stream ,也就是 HTTP/2 可以并行交错地发送请求和响应。
比如下图,服务端并行交错地发送了两个响应: Stream 1 和 Stream 3,这两个 Stream 都是跑在一个 TCP 连接上,客户端收到后,会根据相同的 Stream ID 有序组装成 HTTP 消息。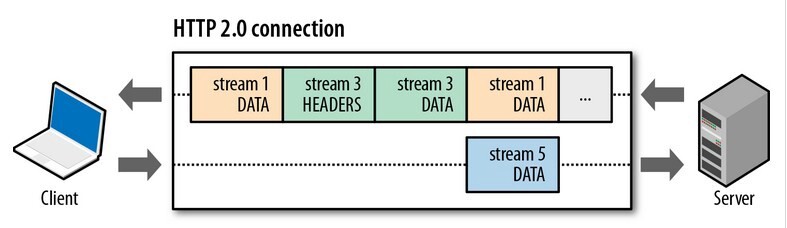
4、服务器推送
HTTP/2 还在一定程度上改善了传统的请求 - 应答工作模式,服务端不再是被动地响应,可以主动向客户端发送消息。
客户端和服务器双方都可以建立 Stream, Stream ID 也是有区别的,客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号。
比如下图,Stream 1 是客户端向服务端请求的资源,属于客户端建立的 Stream,所以该 Stream 的 ID 是奇数(数字 1);Stream 2 和 4 都是服务端主动向客户端推送的资源,属于服务端建立的 Stream,所以这两个 Stream 的 ID 是偶数(数字 2 和 4)。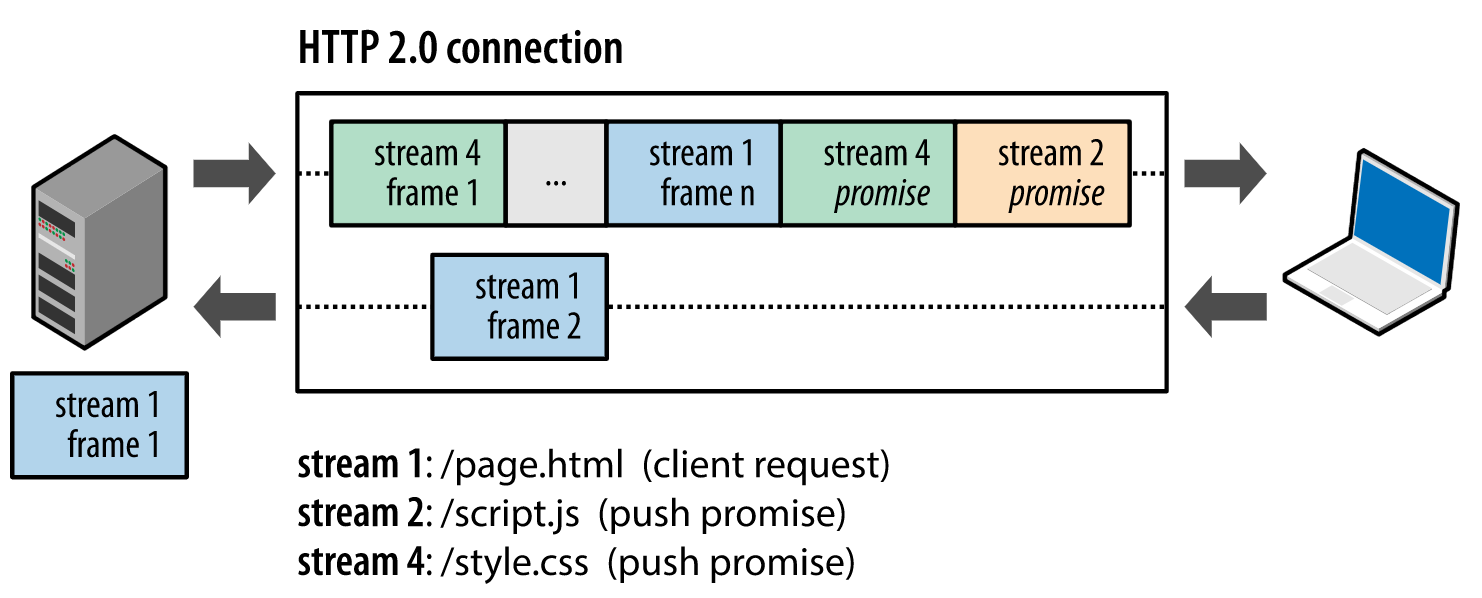
再比如,客户端通过 HTTP/1.1 请求从服务器那获取到了 HTML 文件,而 HTML 可能还需要依赖 CSS 来渲染页面,这时客户端还要再发起获取 CSS 文件的请求,需要两次消息往返,如下图左边部分: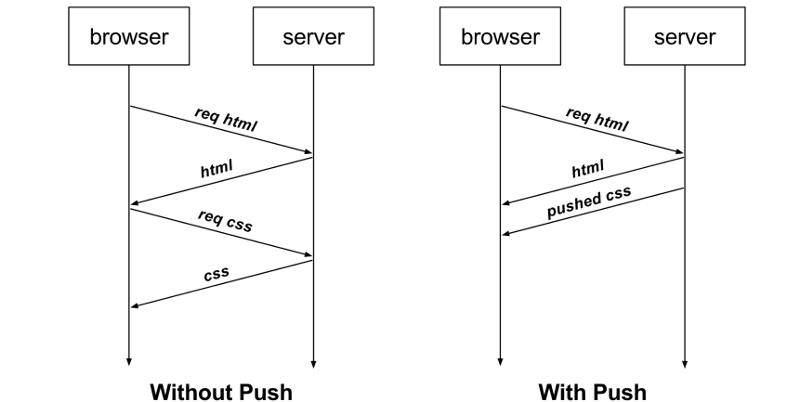
如上图右边部分,在 HTTP/2 中,客户端在访问 HTML 时,服务器可以直接主动推送 CSS 文件,减少了消息传递的次数。
HTTP/2 有什么缺陷?
HTTP/2 通过 Stream 的并发能力,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在“队头阻塞”的问题,只不过问题不是在 HTTP 这一层面,而是在 TCP 这一层。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的,这样内核才会将缓冲区里的数据返回给 HTTP 应用,那么当前 1 个字节数据没有到达时,后收到的字节数据只能存放在内核缓冲区里,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。
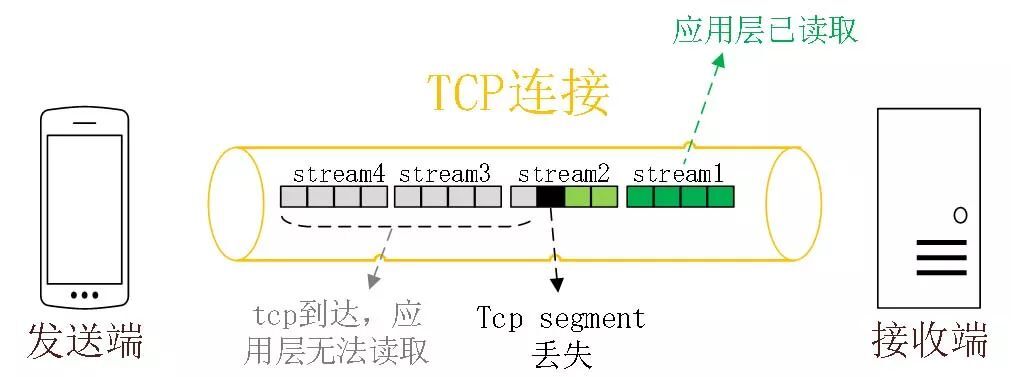
举个例子,如下图:
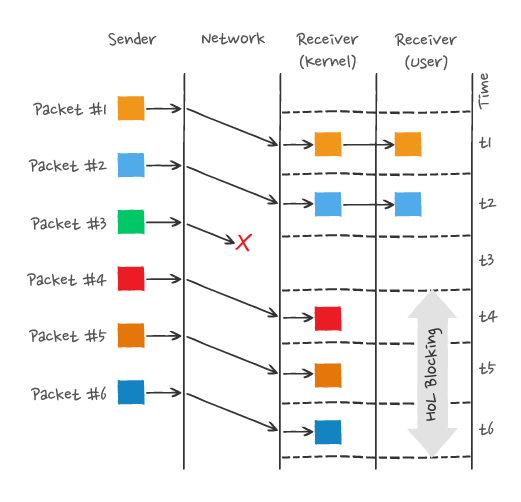
图中发送方发送了很多个 packet,每个 packet 都有自己的序号,你可以认为是 TCP 的序列号,其中 packet 3 在网络中丢失了,即使 packet 4-6 被接收方收到后,由于内核中的 TCP 数据不是连续的,于是接收方的应用层就无法从内核中读取到,只有等到 packet 3 重传后,接收方的应用层才可以从内核中读取到数据,这就是 HTTP/2 的队头阻塞问题,是在 TCP 层面发生的。
所以,一旦发生了丢包现象,就会触发 TCP 的重传机制,这样在一个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来。
HTTP/3 做了哪些优化?
前面知道了 HTTP/1.1 和 HTTP/2 都有队头阻塞的问题:
- HTTP/1.1 中的管道( pipeline)虽然解决了请求的队头阻塞,但是没有解决响应的队头阻塞,因为服务端需要按顺序响应收到的请求,如果服务端处理某个请求消耗的时间比较长,那么只能等响应完这个请求后, 才能处理下一个请求,这属于 HTTP 层队头阻塞。
- HTTP/2 虽然通过多个请求复用一个 TCP 连接解决了 HTTP 的队头阻塞 ,但是一旦发生丢包,就会阻塞住所有的 HTTP 请求,这属于 TCP 层队头阻塞。
HTTP/2 队头阻塞的问题是因为 TCP,所以 HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP!
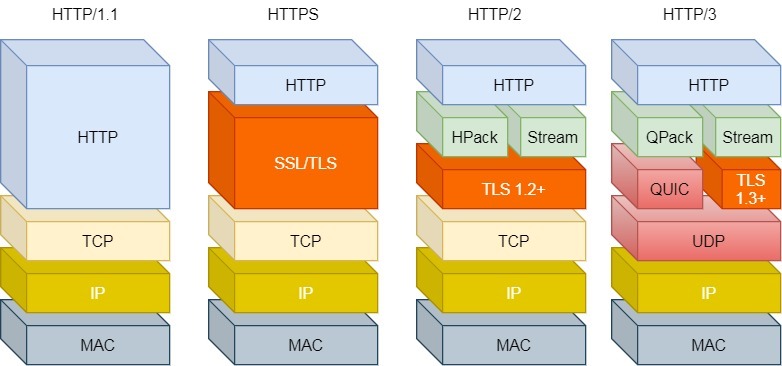
UDP 发送是不管顺序,也不管丢包的,所以不会出现像 HTTP/2 队头阻塞的问题。大家都知道 UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议 可以实现类似 TCP 的可靠性传输。
QUIC 有以下 3 个特点。
- 无队头阻塞
- 更快的连接建立
- 连接迁移
1、无队头阻塞
QUIC 协议也有类似 HTTP/2 Stream 与多路复用的概念,也是可以在同一条连接上并发传输多个 Stream,Stream 可以认为就是一条 HTTP 请求。
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响,因此不存在队头阻塞问题。这与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独立的,某个流发生丢包了,只会影响该流,其他流不受影响。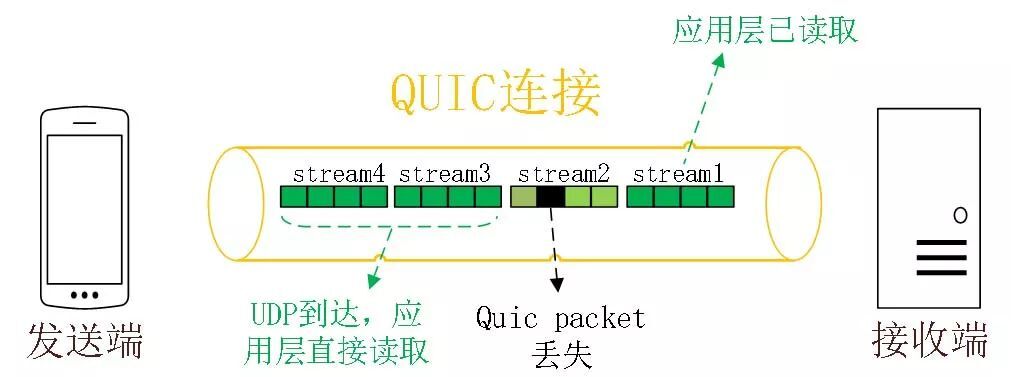
2、更快的连接建立
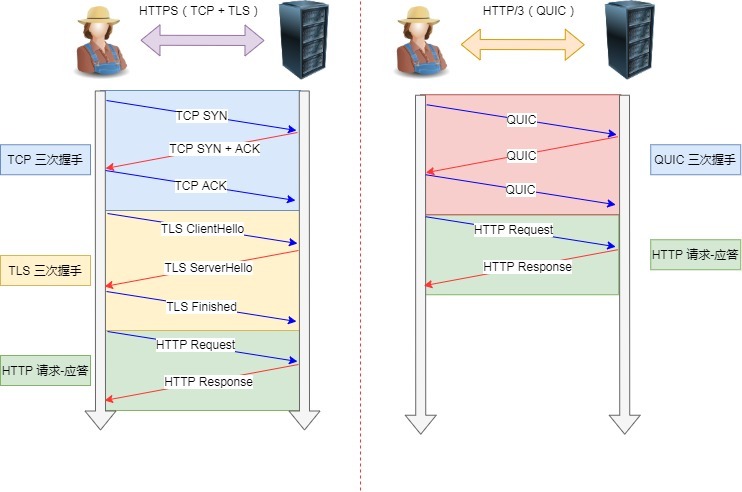
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手,再 TLS 握手。
HTTP/3 在传输数据前虽然需要 QUIC 协议握手,但是这个握手过程只需要 1 RTT,握手的目的是为确认双方的连接 ID,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS/1.3,因此仅需 1 个 RTT 就可以同时完成建立连接与密钥协商,如下图:
甚至,在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
如下图右边部分,HTTP/3 当会话恢复时,有效负载数据与第一个数据包一起发送,可以做到 0-RTT(下图的右下角):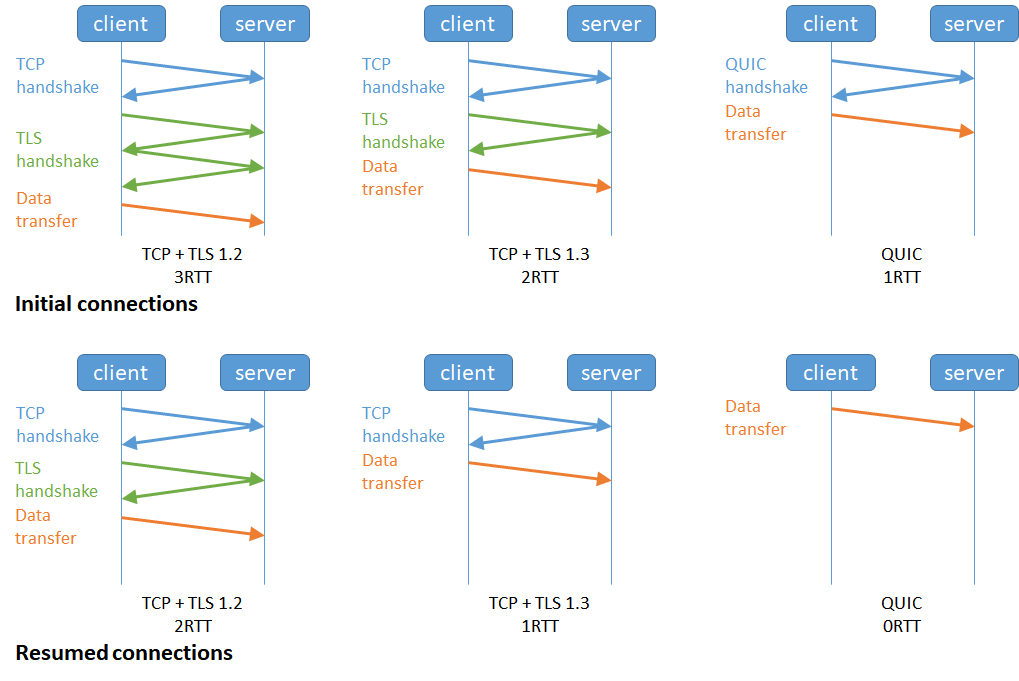
3、连接迁移
基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端口、目的 IP、目的端口)确定一条 TCP 连接。
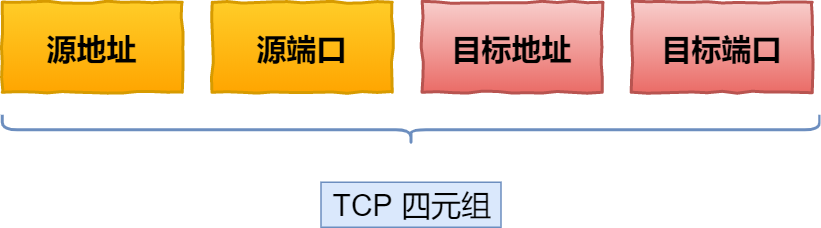
那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接。而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
所以, QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
QUIC 是新协议,对于很多网络设备,根本不知道什么是 QUIC,只会当做 UDP,这样会出现新的问题,因为有的网络设备是会丢掉 UDP 包的,而 QUIC 是基于 UDP 实现的,那么如果网络设备无法识别这个是 QUIC 包,那么就会当作 UDP包,然后被丢弃。
HTTP/3 现在普及的进度非常的缓慢,不知道未来 UDP 是否能够逆袭 TCP。