Day 12

一则小故事
办公楼停电了,小明想上厕所整,到了厕所(共享资源),由于实在太急,小明直接冲入了厕所里,用手摸索着刚好第一个门没锁门,便夺门而入。
这就荒唐了,这个门里面正好小红在上着厕所,正好这个厕所门是坏了的,没办法锁门。
黑暗中,小红虽然看不见,但靠着声音,发现自己面前的这扇门有动静,觉得不对劲,于是铆足了力气,用她穿着高跟鞋脚,用力地一脚踢了过去…
故事说完了,实际上是为了说明,对于共享资源,如果没有上锁,在多线程的环境里,那么就可能会发生翻车现场。
接下来,讲解操作系统中避免多线程资源竞争的互斥、同步的方法。
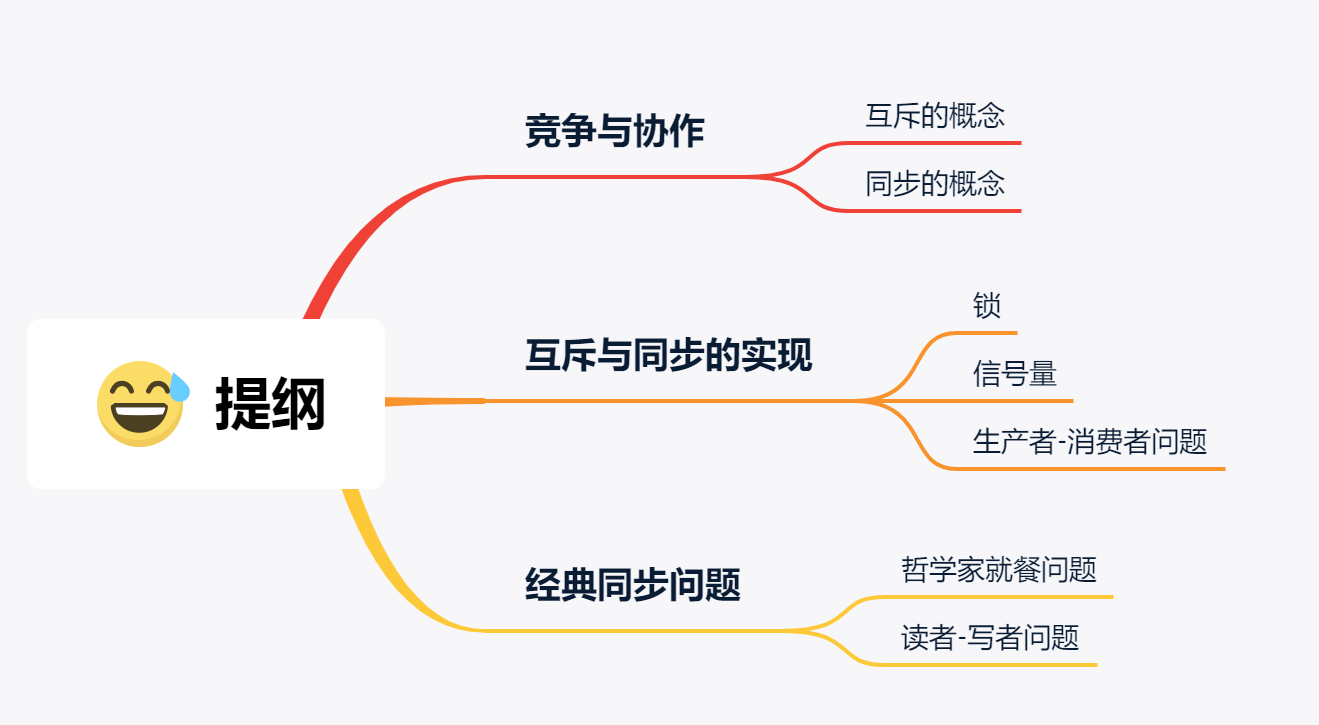
竞争与协作
在单核 CPU 系统里,为了实现多个程序同时运行的假象,操作系统通常以时间片调度的方式,让每个进程执行每次执行一个时间片,时间片用完了,就切换下一个进程运行,由于这个时间片的时间很短,于是就造成了并发的现象。
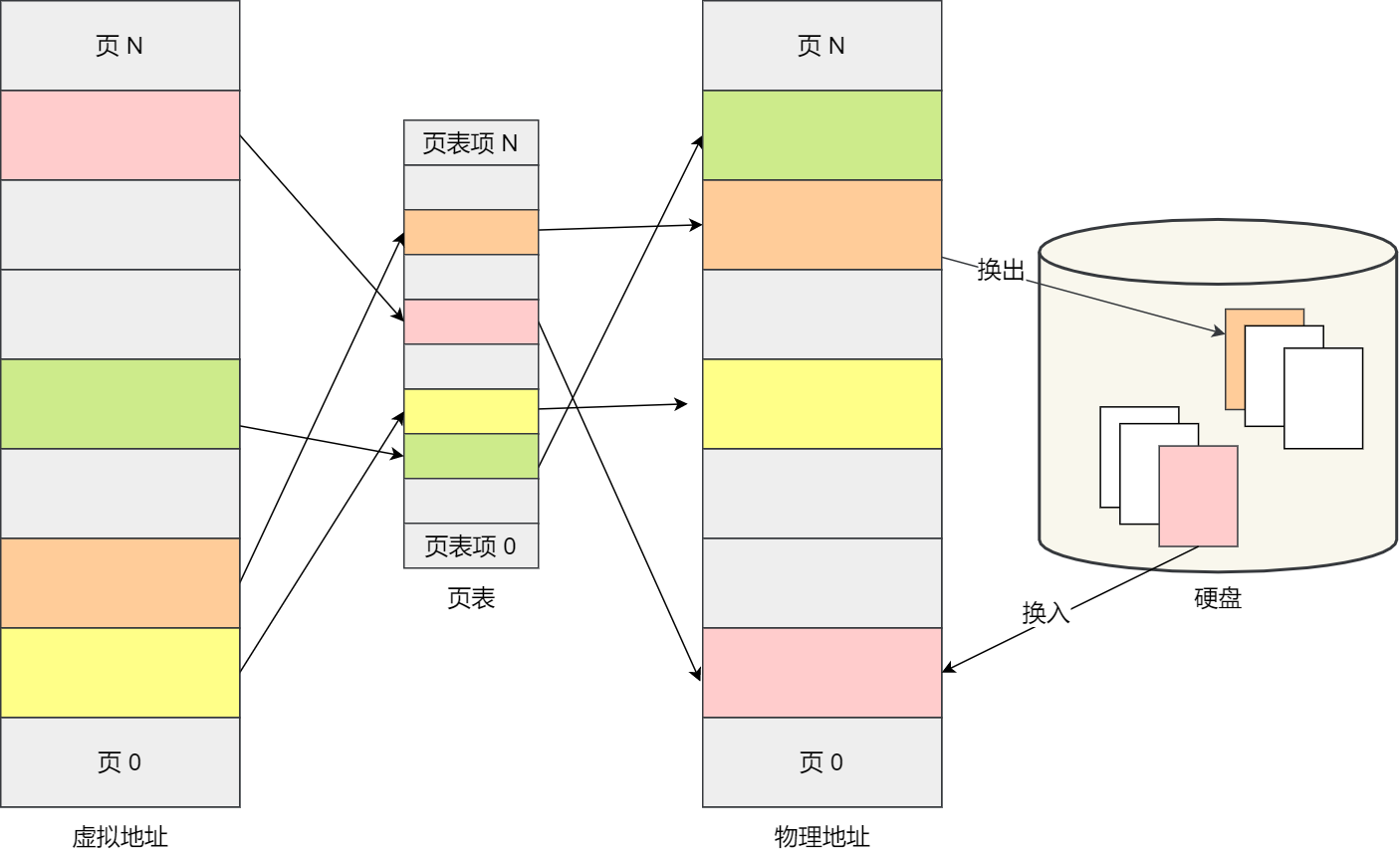
另外,操作系统也为每个进程创建巨大、私有的虚拟内存的假象,这种地址空间的抽象让每个程序好像拥有自己的内存,而实际上操作系统在背后秘密地让多个地址空间复用物理内存或者磁盘。
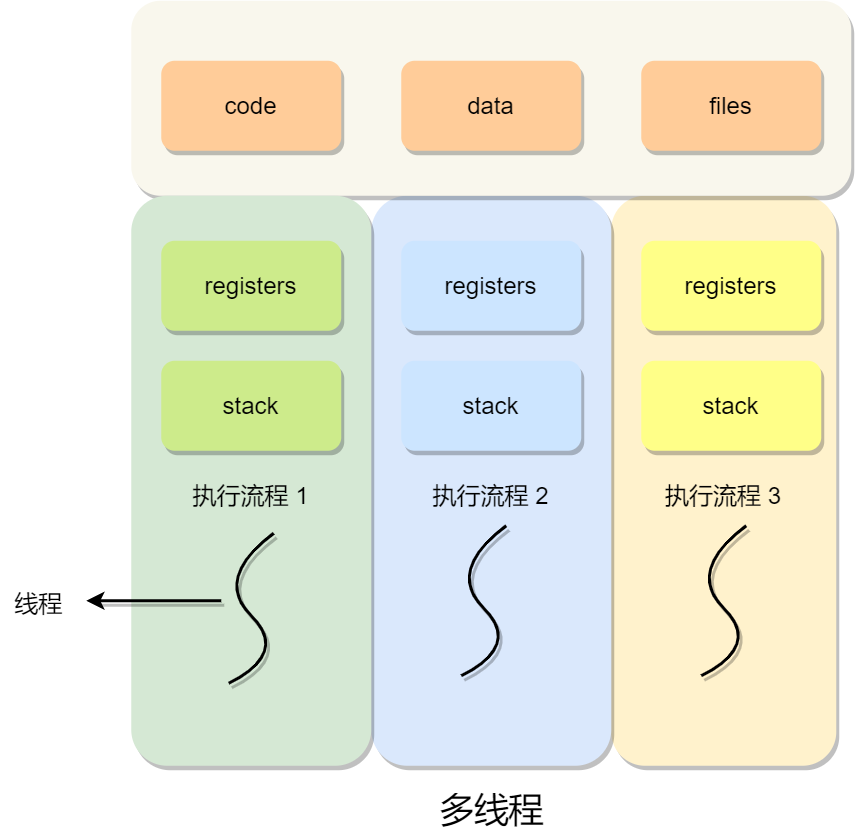
如果一个程序只有一个执行流程,也代表它是单线程的。当然一个程序可以有多个执行流程,也就是所谓的多线程程序,线程是调度的基本单位,进程则是资源分配的基本单位。
所以,线程之间是可以共享进程的资源,比如代码段、堆空间、数据段、打开的文件等资源,但每个线程都有自己独立的栈空间。
多个线程如果竞争共享资源,如果不采取有效的措施,则会造成共享数据的混乱。
做个小实验,创建两个线程,它们分别对共享变量 i 自增 1 执行 10000 次,如下代码:
1 |
|
按理来说,i 变量最后的值应该是 20000,但很不幸,并不是如此。对上面的程序执行一下:
1 | clang++ -g -Wall -o a.out main.cpp |
运行了两次,发现出现了 i 值的结果是 19716,也会出现 20000 的 i 值结果。
每次运行不但会产生错误,而且得到不同的结果。在计算机里是不能容忍的,虽然是小概率出现的错误,但是小概率事件它一定是会发生的,墨菲定律大家都懂吧。
为什么会发生这种情况?
首先必须了解编译器为更新计数器 i 变量生成的代码序列,也就是要了解汇编指令的执行顺序。
在这个例子中,只是想给 i 加上数字 1,那么它对应的汇编指令执行过程是这样的:
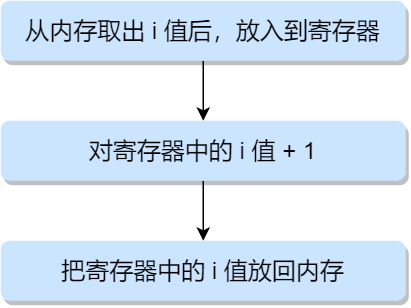
可以发现,只是单纯给 i 加上数字 1,在 CPU 运行的时候,实际上要执行 3 条指令。
设想的线程 1 进入这个代码区域,它将 i 的值(假设此时是 50 )从内存加载到它的寄存器中,然后它向寄存器加 1,此时在寄存器中的 i 值是 51。
现在,一件不幸的事情发生了:时钟中断发生。因此,操作系统将当前正在运行的线程的状态保存到线程的线程控制块 TCB。
现在更糟的事情发生了,线程 2 被调度运行,并进入同一段代码。它也执行了第一条指令,从内存获取 i 值并将其放入到寄存器中,此时内存中 i 的值仍为 50,因此线程 2 寄存器中的 i 值也是 50。假设线程 2 执行接下来的两条指令,将寄存器中的 i 值 + 1,然后将寄存器中的 i 值保存到内存中,于是此时全局变量 i 值是 51。
最后,又发生一次上下文切换,线程 1 恢复执行。还记得它已经执行了两条汇编指令,现在准备执行最后一条指令。回忆一下, 线程 1 寄存器中的 i 值是51,因此,执行最后一条指令后,将值保存到内存,全局变量 i 的值再次被设置为 51。
简单来说,增加 i (值为 50 )的代码被运行两次,按理来说,最后的 i 值应该是 52,但是由于不可控的调度,导致最后 i 值却是 51。
针对上面线程 1 和线程 2 的执行过程,如下图:

互斥的概念
上面展示的情况称为竞争条件(race condition),当多线程相互竞争操作共享变量时,由于运气不好,即在执行过程中发生了上下文切换,得到了错误的结果,事实上,每次运行都可能得到不同的结果,因此输出的结果存在不确定性(indeterminate)。
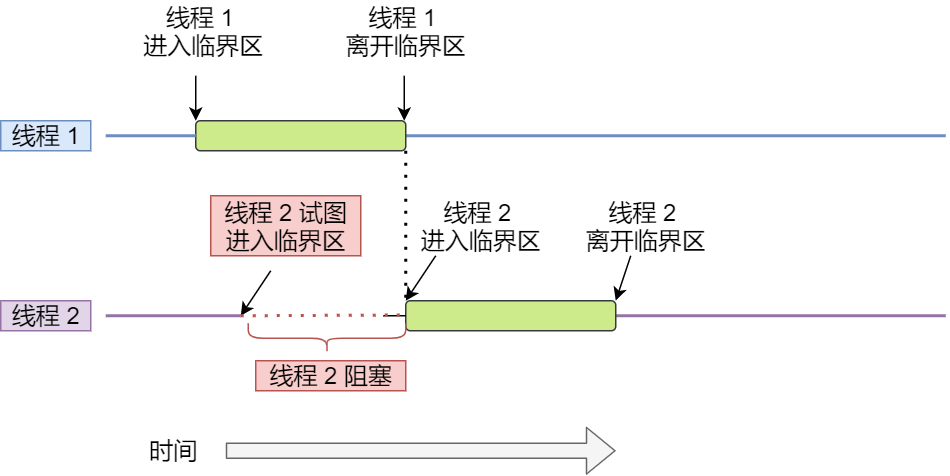
由于多线程执行操作共享变量的这段代码可能会导致竞争状态,因此将此段代码称为临界区(critical section),它是访问共享资源的代码片段,一定不能给多线程同时执行。
希望这段代码是互斥(mutualexclusion) 的,保证一个线程在临界区执行时,其他线程应该被阻止进入临界区,也就是这段代码执行过程中,最多只能出现一个线程。
互斥也并不是只针对多线程。在多进程竞争共享资源的时候,也同样是可以使用互斥的方式来避免资源竞争造成的资源混乱。
同步的概念
互斥解决了并发进程/线程对临界区的使用问题。这种基于临界区控制的交互作用是比较简单的,只要一个进程/线程进入了临界区,其他试图想进入临界区的进程/线程都会被阻塞着,直到第一个进程/线程离开了临界区。
都知道在多线程里,每个线程并不一定是顺序执行的,它们基本是以各自独立的、不可预知的速度向前推进,但有时候又希望多个线程能密切合作,以实现一个共同的任务。
例子,线程 1 是负责读入数据的,而线程 2 是负责处理数据的,这两个线程是相互合作、相互依赖的。线程 2 在没有收到线程 1 的唤醒通知时,就会一直阻塞等待,当线程 1 读完数据需要把数据传给线程 2 时,线程 1 会唤醒线程 2,并把数据交给线程 2 处理。
所谓同步,就是并发进程/线程在一些关键点上可能需要互相等待与互通消息,这种相互制约的等待与互通信息称为进程/线程同步。
举个生活的同步例子,你肚子饿了想要吃饭,你叫妈妈早点做菜,妈妈听到后就开始做菜,但是在妈妈没有做完饭之前,你必须阻塞等待,等妈妈做完饭后,自然会通知你,接着你吃饭的事情就可以进行了。
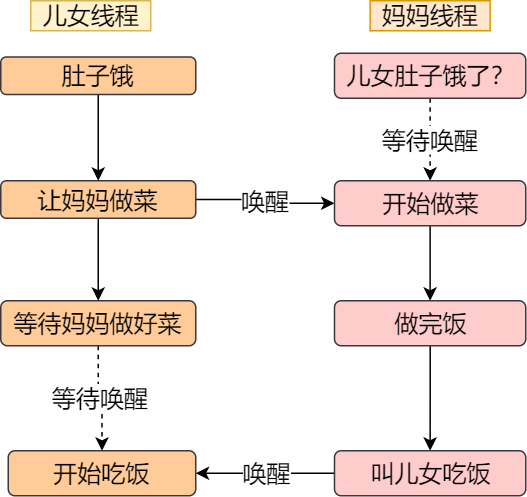
注意,同步与互斥是两种不同的概念:
- 同步就好比:操作 A 应在操作 B 之前执行,操作 C 必须在操作 A 和操作 B 都完成之后才能执行等;
- 互斥就好比:操作 A 和操作 B 不能在同一时刻执行;
锁
多线程访问共享资源的时候,避免不了资源竞争而导致数据错乱的问题,所以通常都会在访问共享资源之前加锁。
最常用的就是互斥锁,当然还有很多种不同的锁,比如自旋锁、读写锁、乐观锁等,不同种类的锁自然适用于不同的场景。
如果选择了错误的锁,那么在一些高并发的场景下,可能会降低系统的性能,这样用户体验就会非常差了。
所以,为了选择合适的锁,不仅需要清楚知道加锁的成本开销有多大,还需要分析业务场景中访问的共享资源的方式,再来还要考虑并发访问共享资源时的冲突概率。
那接下来,针对不同的应用场景,谈一谈互斥锁、自旋锁、读写锁、乐观锁、悲观锁的选择和使用。
互斥锁与自旋锁
最底层的两种就是会互斥锁和自旋锁,有很多高级的锁都是基于它们实现的。
加锁的目的就是保证共享资源在任意时间里,只有一个线程访问,这样就可以避免多线程导致共享数据错乱的问题。
当已经有一个线程加锁后,其他线程加锁则就会失败,互斥锁和自旋锁对于加锁失败后的处理方式是不一样的:
- 互斥锁加锁失败后,线程会释放CPU ,给其他线程;
- 自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
互斥锁 (Mutex)
互斥锁是一种独占锁,比如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放手中的锁,线程 B 加锁就会失败,于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,自然线程 B 加锁的代码就会被阻塞。
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。当加锁失败时,内核会将线程置为睡眠状态,等到锁被释放后,内核会在合适的时机唤醒线程,当这个线程成功获取到锁后,于是就可以继续执行。如下图:
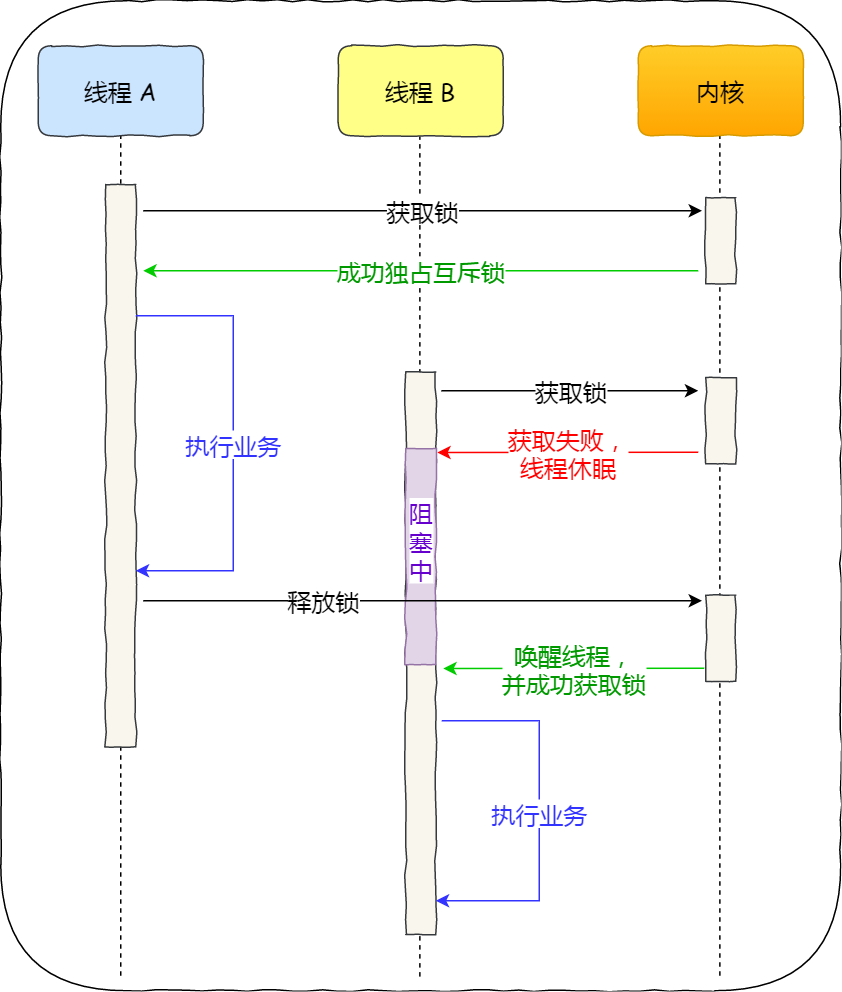
所以,互斥锁加锁失败时,会从用户态陷入到内核态,让内核帮切换线程,虽然简化了使用锁的难度,但是存在一定的性能开销成本。
那这个开销成本是什么呢?会有两次线程上下文切换的成本:
- 当线程加锁失败时,内核会把线程的状态从运行状态设置为睡眠状态,然后把 CPU 切换给其他线程运行;
- 接着,当锁被释放时,之前睡眠状态的线程会变为就绪状态,然后内核会在合适的时间,把 CPU 切换给该线程运行。
线程的上下文切换的是什么?当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
上下切换的耗时,大概在几十纳秒到几微秒之间,如果你锁住的代码执行时间比较短,那可能上下文切换的时间都比你锁住的代码执行时间还要长。
所以,如果能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
自旋锁 (Spin Lock)
自旋锁通过 CPU 提供的 CAS 函数(Compare And Swap),在用户态完成加锁和解锁操作,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。
一般加锁的过程,包含两个步骤:
- 第一步,查看锁的状态,如果锁是空闲的,则执行第二步;
- 第二步,将锁设置为当前线程持有;
CAS 函数就把这两个步骤合并成一条硬件级指令,形成原子指令,这样就保证了这两个步骤是不可分割的,要么一次性执行完两个步骤,要么两个步骤都不执行。
比如,设锁为变量 lock,整数 0 表示锁是空闲状态,整数 pid 表示线程 ID,那么 CAS(lock, 0, pid) 就表示自旋锁的加锁操作,CAS(lock, pid, 0) 则表示解锁操作。
使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会忙等待,直到它拿到锁。这里的忙等待可以用 while 循环等待实现,不过最好是使用 CPU 提供的 PAUSE 指令来实现忙等待,因为可以减少循环等待时的耗电量。
自旋锁是最比较简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。
需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
自旋锁开销少,在多核系统下一般不会主动产生线程切换,适合异步、协程等在用户态切换请求的编程方式,但如果被锁住的代码执行时间过长,自旋的线程会长时间占用 CPU 资源,所以自旋的时间和被锁住的代码执行的时间是成正比。
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用线程切换来应对,自旋锁则用忙等待来应对。
它们是锁的最基本处理方式,更高级的锁都会选择其中一个来实现,比如读写锁既可以选择互斥锁实现,也可以基于自旋锁实现。
读写锁
读写锁从字面意思也可以知道,它由读锁和写锁两部分构成,如果只读取共享资源用读锁加锁,如果要修改共享资源则用写锁加锁。
读写锁适用于能明确区分读操作和写操作的场景。
读写锁的工作原理是:
-
当写锁没有被线程持有时,多个线程能够并发地持有读锁,这大大提高了共享资源的访问效率,因为读锁是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
-
但是,一旦写锁被线程持有后,读线程的获取读锁的操作会被阻塞,而且其他写线程的获取写锁的操作也会被阻塞。
所以写锁是独占锁,因为任何时刻只能有一个线程持有写锁,类似互斥锁和自旋锁,而读锁是共享锁,因为读锁可以被多个线程同时持有。
知道了读写锁的工作原理后,可以发现,读写锁在读多写少的场景,能发挥出优势。
另外,根据实现的不同,读写锁可以分为读优先锁和写优先锁。
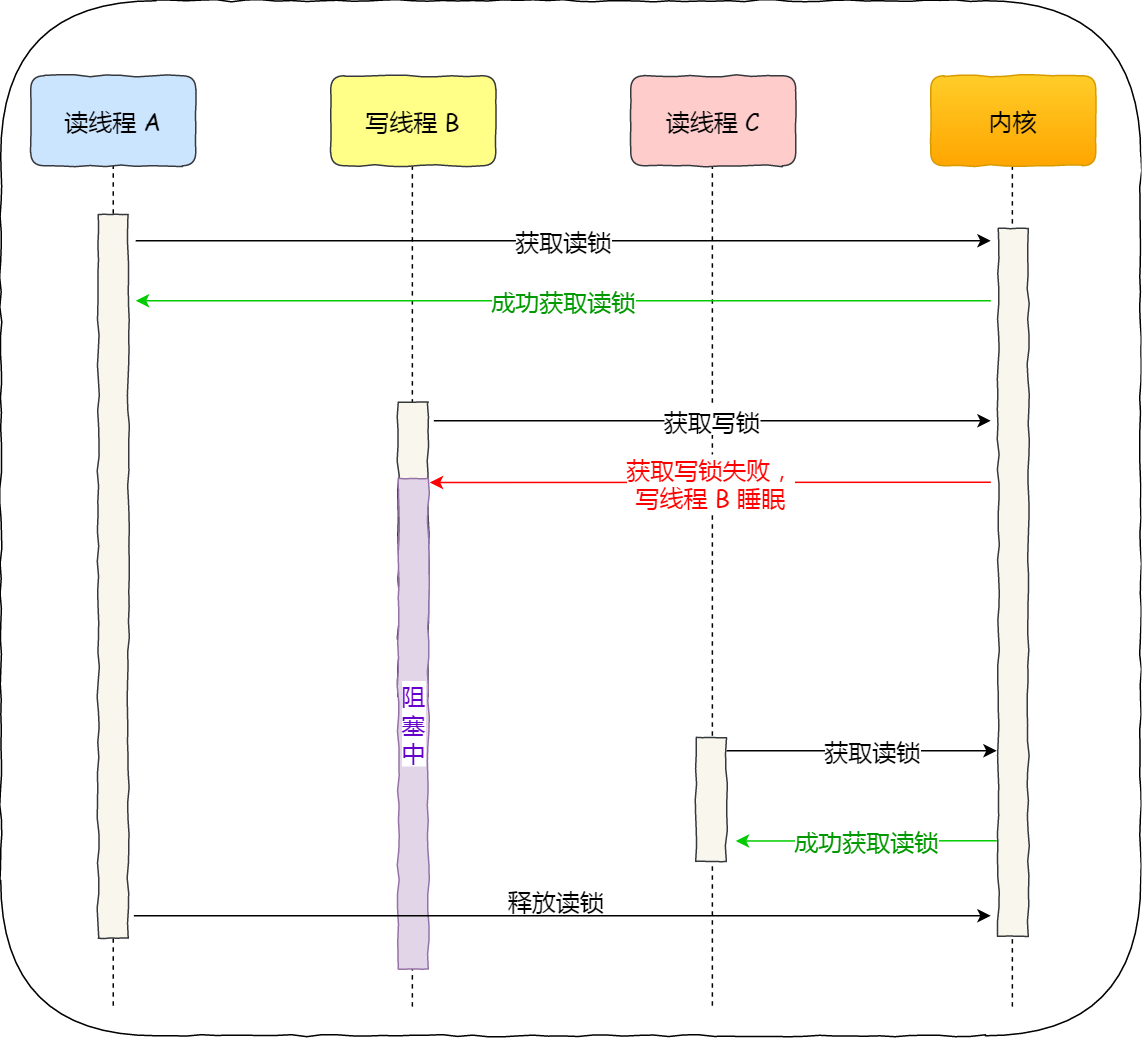
读优先锁
读优先锁期望的是,读锁能被更多的线程持有,以便提高读线程的并发性,它的工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 仍然可以成功获取读锁,最后直到读线程 A 和 C 释放读锁后,写线程 B 才可以成功获取写锁。如下图:
写优先锁
而写优先锁是优先服务写线程,其工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 获取读锁时会失败,于是读线程 C 将被阻塞在获取读锁的操作,这样只要读线程 A 释放读锁后,写线程 B 就可以成功获取写锁。如下图:
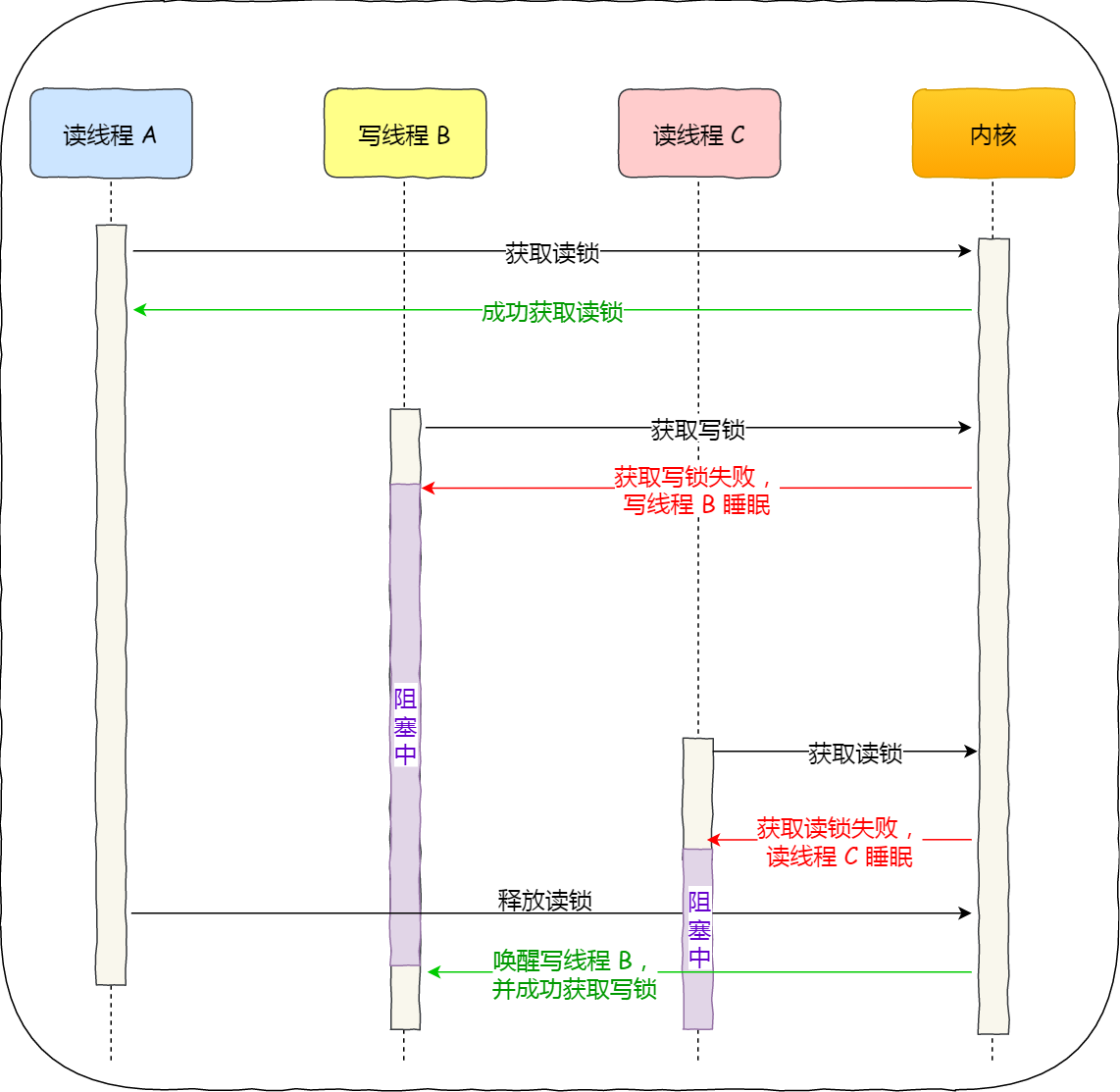
读优先锁对于读线程并发性更好,但也不是没有问题。试想一下,如果一直有读线程获取读锁,那么写线程将永远获取不到写锁,这就造成了写线程饥饿的现象。
写优先锁可以保证写线程不会饿死,但如果一直有写线程获取写锁,读线程也会被饿死。
既然不管优先读锁还是写锁,对方可能会出现饿死问题,那么就不偏袒任何一方,搞个公平读写锁。
公平读写锁比较简单的一种方式是:用队列把获取锁的线程排队,不管是写线程还是读线程都按照先进先出的原则加锁即可,这样读线程仍然可以并发,也不会出现饥饿的现象。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
乐观锁与悲观锁
前面提到的互斥锁、自旋锁、读写锁,都是属于悲观锁。
悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
那相反的,如果多线程同时修改共享资源的概率比较低,就可以采用乐观锁。
乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
放弃后如何重试,这跟业务场景息息相关,虽然重试的成本很高,但是冲突的概率足够低的话,还是可以接受的。
可见,乐观锁的心态是,不管三七二十一,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫无锁编程。
举一个场景例子:在线文档。
在线文档可以同时多人编辑的,如果使用了悲观锁,那么只要有一个用户正在编辑文档,此时其他用户就无法打开相同的文档了,这用户体验当然不好了。
那实现多人同时编辑,实际上是用了乐观锁,它允许多个用户打开同一个文档进行编辑,编辑完提交之后才验证修改的内容是否有冲突。
怎么样才算发生冲突?这里举个例子,比如用户 A 先在浏览器编辑文档,之后用户 B 在浏览器也打开了相同的文档进行编辑,但是用户 B 比用户 A 提交早,这一过程用户 A 是不知道的,当 A 提交修改完的内容时,那么 A 和 B 之间并行修改的地方就会发生冲突。
服务端要怎么验证是否冲突了呢?通常方案如下:
-
由于发生冲突的概率比较低,所以先让用户编辑文档,但是浏览器在下载文档时会记录下服务端返回的文档版本号;
-
当用户提交修改时,发给服务端的请求会带上原始文档版本号,服务器收到后将它与当前版本号进行比较,如果版本号不一致则提交失败,如果版本号一致则修改成功,然后服务端版本号更新到最新的版本号。
实际上,常见的 SVN 和 Git 也是用了乐观锁的思想,先让用户编辑代码,然后提交的时候,通过版本号来判断是否产生了冲突,发生了冲突的地方,需要自己修改后,再重新提交。
乐观锁虽然去除了加锁解锁的操作,但是一旦发生冲突,重试的成本非常高,所以只有在冲突概率非常低,且加锁成本非常高的场景时,才考虑使用乐观锁。
总结
开发过程中,最常见就是互斥锁,互斥锁加锁失败时,会用线程切换来应对,当加锁失败的线程再次加锁成功后的这一过程,会有两次线程上下文切换的成本,性能损耗比较大。
如果明确知道被锁住的代码的执行时间很短,那应该选择开销比较小的自旋锁,因为自旋锁加锁失败时,并不会主动产生线程切换,而是一直忙等待,直到获取到锁,那么如果被锁住的代码执行时间很短,那这个忙等待的时间相对应也很短。
如果能区分读操作和写操作的场景,那读写锁就更合适了,它允许多个读线程可以同时持有读锁,提高了读的并发性。根据偏袒读方还是写方,可以分为读优先锁和写优先锁,读优先锁并发性很强,但是写线程会被饿死,而写优先锁会优先服务写线程,读线程也可能会被饿死,那为了避免饥饿的问题,于是就有了公平读写锁,它是用队列把请求锁的线程排队,并保证先入先出的原则来对线程加锁,这样便保证了某种线程不会被饿死,通用性也更好点。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
另外,互斥锁、自旋锁、读写锁都属于悲观锁,悲观锁认为并发访问共享资源时,冲突概率可能非常高,所以在访问共享资源前,都需要先加锁。
相反的,如果并发访问共享资源时,冲突概率非常低的话,就可以使用乐观锁,它的工作方式是,在访问共享资源时,不用先加锁,修改完共享资源后,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
但是,一旦冲突概率上升,就不适合使用乐观锁了,因为它解决冲突的重试成本非常高。
不管使用的哪种锁,的加锁的代码范围应该尽可能的小,也就是加锁的粒度要小,这样执行速度会比较快。再来,使用上了合适的锁,就会快上加快了。
互斥与同步的实现和使用
在进程/线程并发执行的过程中,进程/线程之间存在协作的关系,例如有互斥、同步的关系。
为了实现进程/线程间正确的协作,操作系统必须提供实现进程协作的措施和方法,主要的方法有两种:
- 锁:加锁、解锁操作;
- 信号量:P、V 操作;
这两个都可以方便地实现进程/线程互斥,而信号量比锁的功能更强一些,它还可以方便地实现进程/线程同步。
加锁和解锁
使用加锁操作和解锁操作可以解决并发线程/进程的互斥问题。
任何想进入临界区的线程,必须先执行加锁操作。若加锁操作顺利通过,则线程可进入临界区;在完成对临界资源的访问后再执行解锁操作,以释放该临界资源。
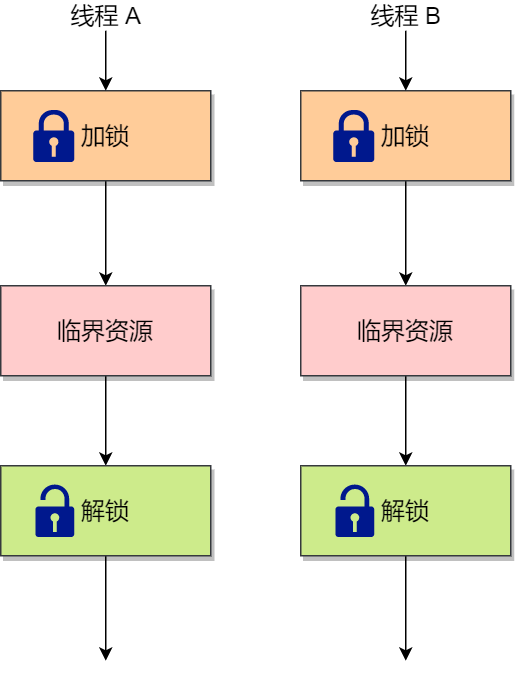
根据锁的实现不同,可以分为忙等待锁和无忙等待锁。
忙等待锁
在说明忙等待锁的实现之前,先介绍现代 CPU 体系结构提供的特殊原子操作指令 —— 测试和置位(Test-and-Set)指令。
如果用 C 代码表示 Test-and-Set 指令,形式如下:
1 | int TestAndSet(int * old_prt, int new) { |
测试并设置指令做了下述事情:
- 把
old_ptr更新为new的新值 - 返回
old_ptr的旧值;
当然,关键是这些代码是原子执行。因为既可以测试旧值,又可以设置新值,所以把这条指令叫作测试并设置。
那什么是原子操作呢?原子操作就是要么全部执行,要么都不执行,不能出现执行到一半的中间状态
可以运用 Test-and-Set 指令来实现忙等待锁,代码如下:
1 | typedef struct lock_t { |
来确保理解为什么这个锁能工作:
-
第一个场景是,首先假设一个线程在运行,调用
lock(),没有其他线程持有锁,所以flag是 0。当调用TestAndSet(flag, 1)方法,返回 0,线程会跳出 while 循环,获取锁。同时也会原子的设置 flag 为1,标志锁已经被持有。当线程离开临界区,调用unlock()将flag清理为 0。 -
第二种场景是,当某一个线程已经持有锁(即
flag为1)。本线程调用lock(),然后调用TestAndSet(flag, 1),这一次返回 1。只要另一个线程一直持有锁,TestAndSet()会重复返回 1,本线程会一直忙等。当flag终于被改为 0,本线程会调用TestAndSet(),返回 0 并且原子地设置为 1,从而获得锁,进入临界区。
很明显,当获取不到锁时,线程就会一直 while 循环,不做任何事情,所以就被称为忙等待锁,也被称为自旋锁(spin lock)。
这是最简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。在单处理器上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
无锁等待
无等待锁顾明思议就是获取不到锁的时候,不用自旋。
既然不想自旋,那当没获取到锁的时候,就把当前线程放入到锁的等待队列,然后执行调度程序,把 CPU 让给其他线程执行。
结构体定义
1 | type struct lock_t{ |
定义了一个锁结构体 lock_t,包含两个成员:
int flag:用于表示锁的状态,0 表示未锁定,1 表示已锁定。queue_t *q:一个指向等待队列的指针,用于存放等待获取锁的线程。
初始化函数
1 | void init(lock_t *lock) |
初始化锁的函数 init,将锁的标志 flag 设为 0 表示未锁定状态,并初始化等待队列。
上锁函数
1 | void lock(lock_t *lock) |
上锁函数 lock 使用 TestAndSet 函数来实现原子操作:
TestAndSet(&lock->flag, 1)是一个原子操作,将flag设置为 1 并返回之前的值。- 如果返回值为 1,表示锁已被其他线程占用,当前线程需要等待。
- 保存当前运行线程的 TCB(线程控制块)信息,将其插入等待队列,并设置为等待状态,然后调用调度程序,让调度程序选择另一个可执行的线程来运行。
- 如果返回值为 0,表示获取锁成功,跳出循环,继续执行。
解锁函数
1 | void unlock(lock_t *lock) |
解锁函数 unlock:
-
当一个线程调用 unlock 函数来释放锁时,首先检查等待队列 q 是否为空。如果等待队列为空,表示没有其他线程在等待这个锁。
-
如果等待队列不为空,执行以下操作:
- 从等待队列中移出第一个等待的线程的 TCB。这个线程是最早等待获取锁的线程,现在它可以被唤醒。
- 将这个线程的 TCB 插入到就绪队列中,使其具备执行条件,等待调度程序安排执行。
- 将这个线程的状态设置为就绪状态,表明它现在可以执行。
-
最后,将锁的标志 flag 设为 0,表示锁已释放。
总结
这个代码实现了一个简单的锁机制,用于线程同步。TestAndSet 函数确保了锁的获取和释放是原子操作,从而避免了竞争条件。等待队列用于存放等待获取锁的线程,解锁时将等待队列中的线程移入就绪队列并设置为就绪状态。
死锁
因为如果线上环境真多发生了死锁,那真的出大事了。系统地聊聊死锁的问题。
- 死锁的概念;
- 模拟死锁问题的产生;
- 利用工具排查死锁问题;
- 避免死锁问题的发生;
死锁的概念
在多线程编程中,为了防止多线程竞争共享资源而导致数据错乱,都会在操作共享资源之前加上互斥锁,只有成功获得到锁的线程,才能操作共享资源,获取不到锁的线程就只能等待,直到锁被释放。
那么,当两个线程为了保护两个不同的共享资源而使用了两个互斥锁,那么这两个互斥锁应用不当的时候,可能会造成两个线程都在等待对方释放锁,在没有外力的作用下,这些线程会一直相互等待,就没办法继续运行,这种情况就是发生了死锁。
举个例子
小林拿了小美房间的钥匙,而小林在自己的房间里,小美拿了小林房间的钥匙,而小美也在自己的房间里。如果小林要从自己的房间里出去,必须拿到小美手中的钥匙,但是小美要出去,又必须拿到小林手中的钥匙,这就形成了死锁。
死锁只有同时满足以下四个条件才会发生:
- 互斥条件;
- 持有并等待条件;
- 不可剥夺条件;
- 环路等待条件;
互斥条件
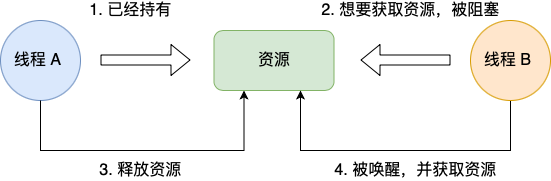
互斥条件是指多个线程不能同时使用同一个资源。
比如下图,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占用的资源,那线程 B 只能等待,直到线程 A 释放了资源。
持有并等待条件
持有并等待条件是指,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。
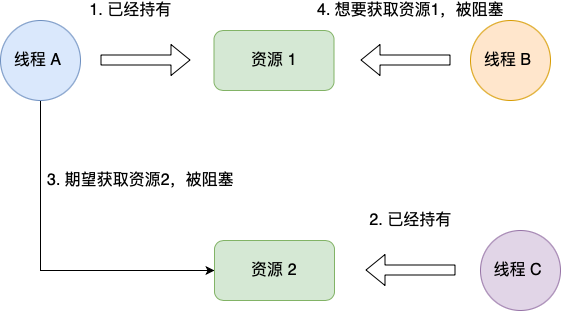
不可剥夺条件
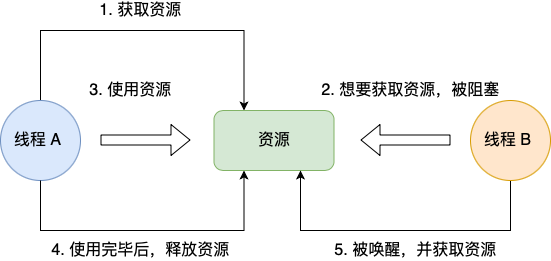
不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。
环路等待条件
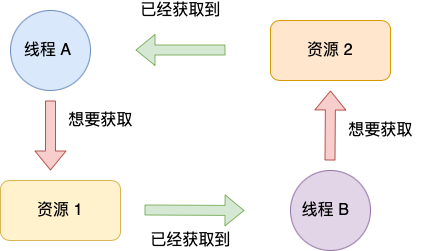
环路等待条件指的是,在死锁发生的时候,两个线程获取资源的顺序构成了环形链。
比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环形图。
模拟死锁问题的产生
Talk is cheap. Show me the code.
下面,用代码来模拟死锁问题的产生。
首先,先创建 2 个线程,分别为线程 A 和 线程 B,然后有两个互斥锁,分别是 mutex_A 和 mutex_B,代码如下:
1 | pthread_mutex_t mutex_A = PTHREAD_MUTEX_INITIALIZER; |
接下来,看下线程 A 函数做了什么。
1 | //线程函数 A |
可以看到,线程 A 函数的过程:
- 先获取互斥锁 A,然后睡眠 1 秒;
- 再获取互斥锁 B,然后释放互斥锁 B;
- 最后释放互斥锁 A;
1 | //线程函数 B |
可以看到,线程 B 函数的过程:
- 先获取互斥锁 B,然后睡眠 1 秒;
- 再获取互斥锁 A,然后释放互斥锁 A;
- 最后释放互斥锁 B;
然后,运行这个程序,运行结果如下:
1 | thread B waiting get ResourceB |
可以看到线程 B 在等待互斥锁 A 的释放,线程 A 在等待互斥锁 B 的释放,双方都在等待对方资源的释放,很明显,产生了死锁问题。
利用工具排查死锁问题
如果你想排查你的 Java 程序是否死锁,则可以使用 jstack 工具,它是 jdk 自带的线程堆栈分析工具。
在 Linux 下,可以使用 pstack + gdb 工具来定位死锁问题。
pstack 命令可以显示每个线程的栈跟踪信息(函数调用过程),它的使用方式也很简单,只需要 pstack <pid> 就可以了。
那么,在定位死锁问题时,可以多次执行 pstack 命令查看线程的函数调用过程,多次对比结果,确认哪几个线程一直没有变化,且是因为在等待锁,那么大概率是由于死锁问题导致的。
用 pstack 输出了前面模拟死锁问题的进程的所有线程的情况,多次执行命令后,其结果都一样,如下:
1 | $ pstack 87746 |
可以看到,Thread 2 和 Thread 3 一直阻塞获取锁(pthread_mutex_lock)的过程,而且 pstack 多次输出信息都没有变化,那么可能大概率发生了死锁。
但是,还不能够确认这两个线程是在互相等待对方的锁的释放,因为看不到它们是等在哪个锁对象,于是可以使用 gdb 工具进一步确认。
- 通过
info thread打印了所有的线程信息,可以看到有 3 个线程,一个是主线程(LWP 87746),另外两个都是自己创建的线程(LWP 87747 和 87748); - 通过
thread 2,将切换到第 2 个线程(LWP 87748); - 通过
bt,打印线程的调用栈信息,可以看到有 threadB_proc 函数,说明这个是线程 B 函数,也就说 LWP 87748 是线程 B; - 通过
frame 3,打印调用栈中的第三个帧的信息,可以看到线程 B 函数,在获取互斥锁 A 的时候阻塞了; - 通过
p mutex_A,打印互斥锁 A 对象信息,可以看到它被 LWP 为 87747(线程 A) 的线程持有着; - 通过
p mutex_B,打印互斥锁 B 对象信息,可以看到他被 LWP 为 87748 (线程 B) 的线程持有着;
因为线程 B 在等待线程 A 所持有的 mutex_A, 而同时线程 A 又在等待线程 B 所拥有的mutex_B, 所以可以断定该程序发生了死锁。
避免死锁问题的发生
产生死锁的四个必要条件是:互斥条件、持有并等待条件、不可剥夺条件、环路等待条件。
那么避免死锁问题就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破环环路等待条件。
那什么是资源有序分配法呢?
线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。
使用资源有序分配法的方式来修改前面发生死锁的代码,可以不改动线程 A 的代码。
先要清楚线程 A 获取资源的顺序,它是先获取互斥锁 A,然后获取互斥锁 B。
所以只需将线程 B 改成以相同顺序的获取资源,就可以打破死锁了。
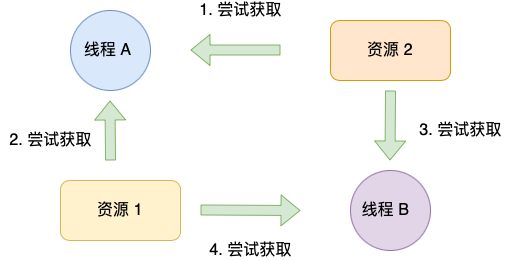
线程 B 函数改进后的代码如下:
1 | //线程 B 函数,同线程 A 一样,先获取互斥锁 A,然后获取互斥锁 B |
执行结果如下,可以看,没有发生死锁。
1 | thread B waiting get ResourceA |
总结
简单来说,死锁问题的产生是由两个或者以上线程并行执行的时候,争夺资源而互相等待造成的。
死锁只有同时满足互斥、持有并等待、不可剥夺、环路等待这四个条件的时候才会发生。
所以要避免死锁问题,就是要破坏其中一个条件即可,最常用的方法就是使用资源有序分配法来破坏环路等待条件。